هذه الأيام نحن معتادون على الوصول لأجهزة الحاسب كلما كنا في حاجة لها، الأمر لم يكن كذلك بالنسبة ل Richard Hamming الباحث الذي كان يعمل في معامل بل في 1940م، حيث أن جهاز الشركة الذي يحتاجه للعمل يستخدم ايضاً بواسطة أقسام أخرى في الشركة، ولا يستطيع الوصول له الا في عطل اخر الأسبوع Weekends، يمكنك ان تتخيل مدى الإحباط الحاصل بعد كتابتك للبرنامج وبسبب حدوث خطأ واحد يتطلب منك ان تقوم باعادة كتابة البرنامج مرة اخرى، يقول هامنغ:
“بعد أسبوعين من العمل جئت ووجدت أن برنامجي وحسباتي توقفت وكأن شيئاً لم يكن، لقد اثار ذلك ازعاجي لأنه ذهب عمل أسبوعين، وقد تساءلت: إذا كان الجهاز يمكن الكشف عن الخطأ، فلماذا لا يمكن تحديد موقع الخطأ ومن ثم تصحيحه؟”
وكما هو المثل الحاجة أم الاختراع، فقد قام هامنغ فيما بعد بإنشاء اول خوارزمية لتصحيح الأخطاء Error Correction Code، وهي خوارزمية تقوم باكتشاف الخطأ وتصحيحه على النظام، وبدون هذه الفكرة فإن أنظمة الحواسيب والاتصالات لن تكون بنفس السرعة drastically slower، والموثوقية less reliable مثل ما نراه ونستخدمه في كل يوم.
الحاجة لل Error Detection وال Error Correction
أحد أهم وظائف الحواسيب التي نستخدمها هي اجراء الحسابات Computations وذلك عن طريق المدخلات المطلوبة ويقوم الحاسب بالعمل عليها لكي يخرج لنا المخرجات المطلوبة.
ولكن حتى يستطيع الحاسب القيام بالاجابه بشكل صحيح فسوف يحتاج الى حفظ تلك البيانات Storing سواء على الذاكرة أو الأقراص، وارسالها Transmitting عبر أي وسيط، وبدون تلك الخاصيتين فسوف يكون الحاسب مشابه للألة الحاسبة فقط ولن يكون مفيداً مثل الحواسيب التي تستخدمها حيث أنك لن تستطيع ارسال البيانات أو حفظها للرجوع اليها فيما بعد، لذلك خاصية الحفظ Storing والارسال Transmitting مهمات لأي حاسوب في الوقت الحاضر.
التحدي المرتبط لهذه العمليتان هو أنه يجب أن يتم تخزين وارسال البيانات كما هي بالضبط، لأنه في بعض الحالات قد يؤدي خطأ صغير واحد في هذه البيانات لتحويلها الى شكل عديم الفائدة، تخيل أنك قمت بحفظ رقم هاتف صديقك على الحاسب فأنت تريد هذه العملية أن تتم بالضبط ويتم تخزين الرقم كما هو لأن أي خطأ في رقم واحد قد يؤدي لك نتيجة خاطئة سواء رقم لشخص أخر أو رقم خاطئ من الأساس، هذا مثال فقط وتزداد الأهمية في حالة الأنظمة الأكثر حساسية مثل الأنظمة المالية والبنكية فقد يؤدي عدم الدقه في الحفظ الى خسارة حقيقة في الأموال الموجودة وهذا أمر غير مقبول.
بالمقارنه مع الأنظمة الورقية فأن البشر لديهم أخطاء في التسجيل والكتابه وقد يمكن تجنبها من خلال توخي الحرص والمراجعة خصوصاً في البيانات الحساسة مثل أرقام الحسابات والرصيد البنكي، ولكن بالنسبة للحواسيب فيجب أن لا يكون هناك خطأ على الاطلاق!
لنفترض أن هناك حاسب مساحة القرص به هو 100 غيغا بايت (ولنقل انها تساوي 15 مليون صفحة نصية)، فاذا كان الحاسب يعطي خطأ واحد لكل مليون صفحة فهذا يعني أن هناك 15 خطأ في هذا الحاسب، وبنفس الفكرة عند ارسال البيانات فاذا قمت بتحميل ملف 20 ميغا بايت من الانترنت وكان هناك خطأ واحد في كل مليون بايت فيه ، فهناك 20 بايت خطأ في هذا البرنامج وهذا قد يؤدي الى فشل Crash البرنامج من العمل.
الخلاصه أن حتى الحواسيب التي لها صحة 99.9999% لا تعتبر جيدة ولا يجب أن يعتمد عليها في الارسال والتخزين ولو كان الخطأ واحد في كل بليون بايت من البيانات.
لكن الحواسيب يجب أن تتعامل مع مشاكل الاتصال Communications التي تتعرض لها الأجهزة الاخرى، مثل الهواتف فإن عملية ارسال الصوت الى الطرف الأخر قد يصل بشكل مشوش وغير واضح، وبنفس الأمر اشارات الأجهزه اللاسلكية Wireless تتعرض لنفس التشويش، ايضاً اقراص التخزين مثل ال CD, DVD يمكن أن تتخدش ووتعرض للغبار والأتربة، فكيف يمكن أن تضمن التعامل مع بلايين البيانات بدون حدوث أخطاء اثناء الحفظ والارسال كما تتعرض لها الأجهزة الأخرى.
سوف نتحدث في هذا الموضوع حول أحد الأفكار العظيمة في علوم الحاسوب والتي ان استخدمتها بشكل صحيح فسوف يمكن ارسال البيانات بمعدل خطأ قليل جداً حتى في أكثر الوسائط المعرضه للتشويش Unreliable Channels وفي الواقع بشكل عملي يكون معدل الخطأ هو صفر.
فكرة التكرار Repetitions
الفكرة الأساسية التي يمكنك من خلالها ارسال البيانات عبر وسيط قابل للتشويش Unreliable Channel هي عن طريق تكرار البيانات أكثر من مرة، وهذا هو رد الفعل الطبيعي عندما تتحدث لشخص عبر الهاتف وحدث تشويش وأبلغك بأنه لم يسمع العباره السابقة فسوف تقوم بتكرار ما قلته مرة أخرى ، أو عندما ترسل رقم عبر الهاتف تقوم بتكراره مره أخرى للتأكد من الرقم صحيحاً ولا يوجد به أخطاء
الحواسيب يمكنها أن تقوم بنفس الفكرة، لنفرض أنك تحول المبلغ 5213.75 الى رصيدك من بنك الى آخر، ولنفرض أن الشبكة غير موثوقه ومشوشه وأن هناك احتمال خطأ بنسبة 20% في اي رقم مرسل وقد يتغير ذلك الرقم لهذا السبب. بعد أن تمت العملية قمت باستلام مبلغ 5293.75 في رصيدك في الحساب الآخر.
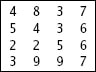
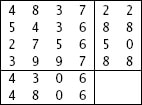
حالياً قد لا تعرف أن العملية صحيحة أو لا، لذلك بدلاً من ارسال الرقم مرة واحدة سوف نطبق فكرة التكرار ونقوم بارسال الرقم أكثر من مرة حتى تعرف الرقم الصحيح، تخيل أنك قمت بتطبيق هذه الفكرة 5 مرات وحصلت على الارقام التالية :
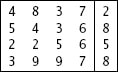
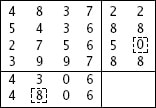
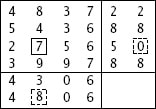
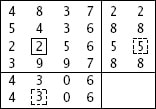
لاحظ أن بعض التحويلات لها أكثر من خطأ واحد وهناك بعض التحويلات ليس لديها أي خطأ (رقم 2 في الصورة السابقة) وحالياً ما زلت لا تعرف أين الخطأ ولن تستطيع أخذ رقم 2 لأنك لا تعرف أين الخطأ. الذي يمكنك فعله هو فحص الأرقام واختيار الرقم الذي تكرر أكثر من غيره، والنتيجة هي موضحه في الصورة بالأسفل في اخر سطر منها:
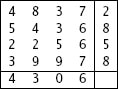
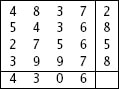
في كل التحويلات (الموجودة في الأعمدة) من 1 الى 4 كان الرقم هو 5 ، بينما في التحويلة 5 احتوت على الرقم 7 (4 تحويلات قالت 5 وواحدة قالت 7) لذلك الاحتمال هنا لصالح ال5. ننتقل الى العمود الثاني وسوف ترى الاحتمال الأغلب هو 2 وهكذا بنفس الأمر في العمود الثالث الرقم 1 هو الأكثر تكراراً، وهكذا للبقية وسوف تكون النتيجة هي 5213.75 وهذا هو الرقم الصحيح.
حتى هذه اللحظة قد حللنا المشكلة بشكل جزئي ولكن في الأعلى كان احتمال الخطأ في الرقم هو 20% وهناك بعض الوسائط لها نسبة خطأ أعلى بكثير، النقطة الأخرى أن الرقم قد يصدف ويرسل بشكل خاطئ لكل التكرارات وبالتالي تحصل على نتيجة خاطئة
لحسن الحظ يمكن حل هذه المشاكل عن طريق زيادة عدد التكرارات حتى نحصل على نسبة الوثوقية Reliability التي نرغب بها، على سبيل المثال لو نظرنا للمثال السابق كانت نسبة الخطأ هي 20% ولنقل الآن أصبحت 50%، لذلك يمكن أن نرسل الرصيد 1000 مرة بدلاً من 5 مرات، ولأن نسبة الخطأ هو 50% فنصف البيانات ترسل صحيحة والنصف الأخر يكون خطأ بمعنى في العمود الأول النصف الأول سوف يكون 5 والنصف الآخر سوف يكون ارقام اخرى، هكذا سوف يكون هناك 500 من 5 وحوالي 50 لكل من الأرقام من الى 9 بدون 5، وهكذا لن تحصل على اجابه خاطئة أبداً واذا استخدم البنك هذه الطريقة فقد يعمل ملايين السنين بدون حدوث أي خطأ
الخلاصه هي أنه يمكنك زيادة الاعتمادية عن طريق زيادة التكرار (وللتنبيه الأخطاء الوارد ذكرها هي الأخطاء العشوائية بسبب تشويش الوسيط وليست الأخطاء الناتجة عن طريق التغيير المتعمد لها، ففكرة التكرار لن تعمل اذا حدث تغيير متعمد للبيانات وهناك طرق اخرى تستطيع اكتشاف ذلك سوف يتم تناولها في اخر الموضوع).
هكذا باستخدام فكرة التكرار Repetition فقد تم حل مشكلة الارسال على وسيط مشوش ولكن لسوء الحظ فهذه الفكرة ليست مناسبة للحواسيب حيث أن عملية الارسال المتكرر (ارسال الرصيد 1000 مرة) يكون مكلفاً (تخيل ارسال 200 ميغا بايت لتحميل برنامج بتكرار 1000 مرة) لذلك تحتاج الحواسيب لفكرة اخرى أكثر عملية من فكرة التكرار.
فكرة ال Redundancy
قد تتسائل لماذا تم شرح فكرة التكرار بينما هي في الواقع غير عملية وغير مستخدمة ؟ السبب أنها تمثل الفكرة الأساسية في ارسال البيانات عبر الوسيط المشوش لأنك لن ترسل الرسالة الأصلية فقط بل سوف ترسل معها شيء اضافي يزيد من موثوقية الرسالة. في فكرة التكرار كان الشيء الأضافي هو نسخ اخرى من الرسالة الأصلية، لكن هناك أمور أخرى يمكن أن تكون اضافيه للرسالة حتى تزيد الموثوقية، وعلماء الحاسوب يسموا هذه الزيادة ب Redundancy وهي تكون اما باضافه الى الرسالة الأصلية أو عن طريق تحويل الرسالة الى رسالة أطول وعندما تستلم الرسالة يتم تحويلها حتى لو حصل لها تشويش بسبب وسيط النقل poor communication channel.
مثال لتوضيح الفكرة، لنرجع لنفس المثال السابق لارسال الرصيد البنكي 5213.75$ عن طريقة وسيط اتصال غير موثوق والذي يقوم بشكل عشوائي بتعديل 20% من الأرقام.
الان بدلاً من ارسال الرصيد 5213.75$ سوف نقول بتحويلها الى رسالة أطول (رسالة Redundant) تحتوى على نفس المعلومات بالضبط، وسوف نقوم بكتابة الأرقام كتابة بالانجليزي، وسوف تصبح الرسالة:
five two one three point seven five
الان تم ارسال البيانات وحصل فقدان ل20% منها، سوف تصبح الرسالة الناتجه هي:
fiqe kwo one thrxp point sivpn fivq
بالرغم من أنها مزعجة في القرائه، لكن ما زال بامكان أي شخص يعرف الانجليزية أن يخمن الأرقام المفقودة ويحصل على الرصيد الصحيح.
الفكرة هنا أننا بسبب استخدمنا فكرة ال Redundant Message فأصبح بمكاننا اكتشاف الخطأ وتصحيحه في الرسالة، فاذا قلت لك ان fiqe هي رقم وهناك خطأ في حرف واحد فسوف تستطيع معرفته بسهولة، وهذا عكس ما اذا قلت لك ان الرقم 367 يمثل رقم وهناك رقم واحد تم فقدانه فسوف يستحيل معرفته والسبب عدم وجود اي redundancy في الرسالة.
حتى الان لم نرى كيف تعمل فكرة ال redundancy لكن فقط رأينا أن لها علاقه بجعل الرسالة اطول وكل جزء من الرسالة مربتط بنمط معين well-known pattern. وبهذا الشكل يمكن اكتشاف اي تعديل على الجزء لأنه لن ينطبق على النمط ومن ثم نستطيع تعديله حتى ينطبق مع النمط الصحيح.
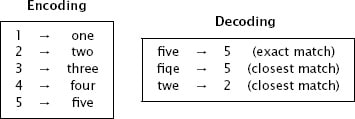
علماء الحاسوب يسموا هذه الأنماط Patterns بالاسم Code Word، في مثالنا السابق كان ال code words هي الارقام مكتوبة بالانجليزية مثل one, two, three وهكذا.
حان الوقت لشرح فكرة الRedundancy والرسالة بشكل عام مكون من رموز Symbols (في مثالنا السابق هي الأرقام من 0 الى 9) وسوف نتجاهل علامة $ والفاصلة العشرية الان لتوضيح الفكرة الأساسية بشكل أبسط، كل رمز Symbol سوف يعطى قيمة من ال code work، في مثالنا الرمز 1 اعطي القيمة one من الcode word، و الرمز 2 سوف يعطي القيمة two وهكذا.
بعد أن تقوم بالعملية لكل الرموز لديك وتقوم بأرسالها وتصل للطرف الاخر، سوف يقوم بالنظر لكل جزء منها والتأكد هي تمثل code word صحيح، اذا كانت تمثل بشكل صحيح مثلاً five فسوف نعطيها القيمة المقابلة لذلك الرمز 5، واذا لم تكن صحيحة مثلاً fiqe سوف نبحث عن اقرب code word تطابق ذلك القيمة وهي five وهكذا تكتشف خطأ وتعطيه القيمة 5.
الصورة التالية هي مثال لما يحدث:
هذا كل ما في الأمر، والحواسيب تستخدم هذه الفكرة طول الوقت لتخزين وارسال المعلومات ولكن بجدول اصلح للحواسيب كما في الصورة التالية، وهي مثال ل Hamming Code والتي اكتشفها ريتشارد هامنغ في معامل بل Bell Lap في 1947 وذلك لحل مشكلة تعطل crash الحاسب التي ذكرناها في أول الموضوع، والفرق في هذه الجدول أنه يتعامل مع الصفر والواحد فقط (وهو يسمى 7,4 Hamming Code).
سوف تعمل هذه الطريقة كما وضحناها سابقاً، فعندما ترمز رسالة Encoding Message، فكل مجموعه من 4 ارقام يضاف اليها زيادة، وبالتالي توليد code word من سبعه ارقام digits. عندما تقوم بعمل ال decoding سوف تنظر للمطابق من ال7 ارقام التي وصلتك، واذا لم تجد فسوف تأخذ أقرب مطابق لها.
من المهم معرفة لماذا يفضل ال Redundancy Trick على فكرة التكرار Repetition Trick؟ والسبب الأساسي هو في التكلفة Cost وعلماء الحاسوب يسموا التكلفة في ال error correction systems بالاسم ال overhead وهي مقدار المعلومات الاضافيه التي تحتاج لارسالها مع الرسالة لكي تضمن انها تصل بشكل صحيح. فال overhead في فكرة التكرار كبير لأنك تحتاج لأن ترسل عدة نسخ من الرسالة، بينما في ال redundancy فهذا يعتمد على ال code words الذي تستخدمه، مثلاً في المثال السابقة English Words فالرسالة الناتجه هي بطول 35 حرف بينما الرسالة الاصلية هي كانت 6 ارقام وكما هو واضح فان ال overhead ايضاً كبير. لكن اذا استخدمت code word افضل له اقل redundancy سوف تحصل على اداء افضل واقل overhead، ولهذا السبب الحواسب تستخدم فكرة ال redundancy بدلاً من فكرة التكرار.
لاحظ أن الحديث ينطبق على التخزين ايضاً وليس فقط الارسال سواء على الCD, DVDs, Hard Disks فكلها تعتمد على انظمة تصحيح الاخطاء لضمان الموثوقية Reliability التي تراها وتستخدمها كل يوم.
فكرة ال Checksum:
حتى الان تناول بعض الطرق التي تسمح لاكتشاف detect وتصحيح correct الاخطاء في البيانات، باستخدام فكرة التكرار Repetition وفكرة ال Redundancy، لكن هناك طرق لنفس المشكلة، ولنركز الان حول فكرة اكتشاف الأخطاء فقط (بدون التصحيح).
للكثير من التطبيقات فقط اكتشاف الأخطاء يكفيها، لأنه اذا اكتشفت الخطأ فيمكنك ان تقوم بطلب البيانات مرة أخرى، وهكذا حتى تحصل على بيانات بدون أخطاء. هذه الفكرة تستخدم كثيراً، مثلاً كل الاتصالات في الانترنت تستخدم هذه الفكرة، وسوف نسميها checksum trick لسبب سوف تعرفه فيما يلي.
لفهم ال checksum trick، سوف نتعامل الان مع رسائل مكونة من أرقام فقط حتى تستوعب الفكرة بسهولة، وهذا منطقى لأن كل الحواسيب تخزن كل المعلومات على شكل ارقام وتفسر هذه البيانات على شكل نصوص أو صور عندما تعرضها لك. على اي حالة من المهم فهم أن أي مجموعه معينة من الرموز لا تؤثر على الطرق التي وضحانها خلال هذا الموضوع، فقط بعض الأحيان نستخدم الأرقام من 0 الى 9 للسهولة والتركيز على الفكرة، وأحياناً من الاسهل وضع المثال بالأحرف alphabetic symbols من a الى z. لكن ببساطة يمكنك اعطاء الرقم 0 الحرف a والرقم 1 للحرف b وهكذا يمكنك استخدام اي منهم في أي من الامثلة المعروضة سواء كان رقم أو حرف.
هذه اللحظة سوف نعرف ما هي ال checksum وهناك عدة أنواع مختلفة منها، وسوف ناخذ أسهل نوع فيها وهي ال Simple checksum. وحساب ال simple checksum لأي رسالة أمر في غاية البساطة: فكل ما عليك هو اخذ الأرقام في الرسالة وجمعها ومن ثم حذف جميع الأرقام في النتيجة ما عدا اخر رقم منها وهي تكون ال simple checksum.
مثال لدينا الرسالة: 46756 عندما تقوم بحساب الجمع لها سوف تحصل على
4+6+7+5+6 وهو يساوي 28، الان سوف نحذف كل النتيجة ما عدا الرقم الاخير منها وهو 8، هكذا ال simple checksum لهذه الرسالة هو 8.
السؤال الان كيف يستخدم هذا ال checksum؟ وذلك عن طريقة اضافته في اخر الرسالة الاصلية وقبل ان ترسلها، وعندما تصل للطرف الأخر سوف يقوم بحساب ال checksum مرة اخرى ويقارنه بالموجود فاذا تطابق فهذا يعني انه صحيح. لكي تتذكرها بسهولة افهمها على انها check للsum من الرسالة (ولهذا اتي المصطلح checksum).
هكذا سوف ترسل الرسالة: 467568 وعندما تصل الرسالة ويعرف المستقبل أنها تستخدم فكرة ال checksum سوف يقوم بحساب 4+6+7+5+6 ويخرج 28 ويأخذ الرقم الاخير ويقارنه مع الموجود في الرسالة 8 وهكذا يعرف أنه ارسلت بشكل صحيح.
لكن ماذا اذا حصل خطأ وقت الارسال، ووصلت الرسالة ب 463568 (بدل الرقم 7 ب 3 )، وهكذا سوف تحسب الchecksum وتجد أنه 24 ومن ثم اخذ الاخير وهو 4 وهو غير مطابق مع 8 وبالتالي هناك خطأ وقت الارسال، وفي هذه اللحظة يمكن ان تطلب البيانات مرة اخرى والقيام بعمل الفحص مجدداً وسوف تستمر حتى يكون ال checksum صحيحاً.
حتى الان الامور تبدوا جيدة، فهي تعمل ولها overhead قليل (الأقل من منا سبق ultimate low overhead system)، لأنه بغض النظر عن طول الرسالة سوف يضاف رقم واحد فقط اليها the checksum حتى تكتشف الخطأ.
المشكلة هي ال simple checksum يستطيع اكتشاف خطأ واحد فقط في الرسالة، فاذا كان هناك أكثر من خطأ فقد يمكن اكتشافها وقد لا يمكن بهذه الطريقة، لنأخذ مثال:
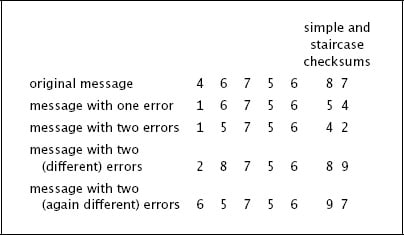
الرسالة الأصلية هي 46756 وال checksum لها هو 8، في السطر الثاني هناك خطأ واحد (الرقم الأول اصبح 1 بدلاً من 4) ولذلك ال checksum اصبح مختلفاً 5، السطر الثالث هناك خطئين وتم اكتشاف الخطأ لأنه الchecksum اصبحت 4، المشكلة التي نتحدث عنها هي في السطر الرابع حيث هناك خطئين ايضاً ولكن الchecksum حسب بأنه 8 وبالتالي لن يتم اكتشاف اي خطأ في هذه الرسالة بالرغم من وجود رقمين خاطئين بها.
لحل هذه المشكلة يمكن أن نضيف بعض التعديلات على فكرة ال checksum وسوف نطلق على التعديل الجديد بالاسم staircase checksum (نسبة للدرج) وسميناها كذلك لأنه فكرتها كأنك سوف تصعد درج اثناء الحساب. وتخيل أنك بأسفل الدرج وكل درج مرقم من 1و2و3 وهكذا.
لحساب ال staircase checksum سوف تضيف الأرقام كما في السابق لكن كل رقم سوف تضربه برقم الدرج (الخانة) الذي انت فيه، وهكذا تصعد خطوة لكل رقم تريد حسابه، وفي النهايه سوف تحذف كل شيء ما عدا الرقم الاخير.
مثال لدينا نفس الرسالة 46756 وسوف نقوم بحساب بضرب رقم الخانه لكل رقم في الرسالة (اول رقم سوف ينضرب في 1، ثاني رقم في 2 ، وهكذا).
وسوف تحذف الرقم الاخير وبالتالي ال staircase checksum هو 7.
الان اذا تم دمج ال simple و ال staircase مع بعضهما البعض سوف تستطيع اكتشاف اي خطئين في الرسالة. هكذا الان سوف نرسل الرسالة وبها رقمان في الأخير الأول هو simple checksum والثاني هي staircase checksum، مثلاً الرسالة 46756 سوف تصبح 4675687 ، ولنرى الجدول التالي هو نفس الرسالة السابقة، ولكن بعد اضافه عمود ال staircase checksum:
عندما يكون هناك خطأ واحد فسوف نكتشف الخطأ من خلال الsimple و staircase، وعندما يكون هناك خطئين فمن المحتمل ايضاً ان يكتشف في الاثنين، فمثلاً في السطر الثالث تم اكتشاف الخطأ بالطريقتين، لكن في السطر الرابع فتم اكتشاف الخطأ بطريقة ال staircase checksum، وفي السطر الأخير ايضاً رسالة بها خطئين وتم اكتشاف الخطأ بطريقة ال simple checksum. وخلاصه سوف تستطيع اكتشاف اي اخطاء مكون من اثنين أول أقل بهذه الطريقة.
الان بدئنا باستيعاب المفهموم الأساسي من الفكرة، ويجب معرفة ان فكرة ال checksum تعمل فقط على الرسائل القصيرة (10 ارقام وما أقل)، لكن هناك افكار قريبة منها جداً تعمل على الرسائل الطويلة.
فكرة ال checksum trick اعلاه تخرج رقمين checksum فقط (ال simple والstaircase)، لكن اي checksum حقيقي سوف يكون أطول وربما يصل الى 150 رقم، وهذا رقم صغير مقارنة بحجم الرسائل الكبيرة، مثلاً لو كنت تستخدم checksum من 100 رقم، واستخدمه مع بيانات بحجم 20 ميغابايت (مثلاً برنامج تنزله من الانترنت) فهذه ال100 هي أقل واحد في الألف من 1٪ من حجم البرنامج الأصلي.، وهي أنواع معينة من الchecksum تسمى Hash Function، ايضاً اذا كان من المحتمل ان يتم تعديل البيانات بشكل يدوي أو بواسطة مخرب فمن الأفضل استخدام ال hash function لأنه من الممكن ان يعدل على البيانات الأصلية بحيث تنتج نفس الchecksum حتى لا يتم اكتشاف الخطأ وبالتالي قد يحصل الضرر من ذلك، والأفضل في تلك الحالة هو استخدام ال hash function والذي يضمن أن اي تغيير في رقم واحد سوف ينتج لمخرج مختلف نهائياً عن المخرج الأصلي.
فكرة ال pinpoint
تحدثنا الان عن فكرة الchecksum ، لنرجع الحديث حول المشكلة الأصلي وهي اكتشاف وتصحيح الأخطاء وقد عرفنا طريقة الRepetition وطريقة ال Redundancy، ولننقاش مسألة كيف يمكن توليد ال code words فقد طرحنا مثال الأرقام بالأحرف كتابة ووجدنا أنها أقل كفائه، وايضاً طرحنا مثال على hamming code بدون اي توضيح حول كيف ولدت هذه ال code words من الأساس.
سوف نعرف مجموعه اخرى من ال code wordsالتي يمكن تستخدم في ال Redundancy Trick وسوف نسميها pinpoint لأنها حالة خاصة تسمح لك بايجاد الخطأ بسرعه quickly pinpoint error ومن هنا اتي الاسم pinpoint trick.
سوف نعمل على رسائل بطول 16 ولكن هذا لا يعني ان هناك limit معين ويمكنك تقسيم رسالتك الطويلة الى اجزاء chunks من 16 حرف، واعمل على كل جزء بشكل منفصل، واذا كانت الرسالة أو الجزء الاخير منها اقل من 16 فيمكنك ملء البقية بالأصفر حتى تصل ل16 رقم.
مثلاً الرسالة هي: 4837543622563997 وسوف تبدأ بعملها على شكل مربع من اليمين الى اليسار كما في الشكل التالي:
بعد ذلك تحسب ال simple checksum لكل صف من الصفوف
تذكر الsimple checksum هي مجرد جمع واخذ الرقم الاخير فقط، مثلاً الصف الثاني 4+5+3+6 ويساوي 18 وبالتالي يكون 8.
الخطوة التالية حساب ال simple checksum لكل عمود كما في الشكل:
بعد ذلك عمل تجميع للأرقام بنفس الطريقة التي وضعوا بها من اليسار لليمين وبالتالي الرسالة سوف تكون من 24 خانه هي: 483725436822565399784306 ولنفرض انه حدث خطأ واحد وانك استقبلت الرسالة 483725436827565399784306 سوف نقوم الان بالتأكد منها وتصحيح الخطأ الموجود بهذه الطريقة.
بعد أن وصلت الرسالة 483725436827565399784306 أول خطوة هي وضعها على مربع 5 * 5 كما في الشكل:
الان قم بحساب ال simple checksum لكل اربعه ارقام من لكل صف وعمود وقم باضافتها كما بالشكل:
وكما هو واضح ان لديك الان ال checksum الذي ارسل بالاضافه الى ال checksum الذي قمت بحسابه، وبالطبع اذا تساوت الارقام فهذا يعني صحة الرسالة واذا اختلف فيعني خطأ في هذه الرسالة، وهنا لدينا خطئان:
هكذا موقع الخطأ اصبح معروف: العمود الثاني الصف الثالث، وهو كما موضح ادناه الرقم 7:
الان تم تحديد موقع الخطأ، ولتصحيحه نقوم باستبدال الرقم 7 برقم يجعل حساب ال checksum للعمود والصف صحيح، يمكنك اجراء الحسابات بسهولة، والرقم الصحيح هو 2:
الان تم ايجاد الخطأ وتصحيحه، بقي فقط ايجاد الرسالة الاصلية وهي تكون بتجميع الارقام في الجدول من اليسار الى اليمين واهمال ال checksums وبالتالي تكون الرسالة هي: 4837543622563997 وهي نفس الرسالة الأصلية.
في علوم الحاسب هذه الفكرة اسمها Two Dimensional Parity ، والاسم parity هو مطابق لل simple checksum في الحاسب عندما يتم التعامل مع الارقام الثنائية. هذه ال two dimensional parity استخدمت في بعض الاجهزة لكنها ليست ذات كفائه مقارنة بطرق اخرى، وتم توضيحها فقط لايصال فكرة انه يمكن ايجاد وتصحيح الاخطاء بدون الحاجة لمعادلات رياضية معقدة كما يتم الاعتقاد بذلك.
ايجاد وتصحيح الأخطاء في العالم الحقيقي
ظهرت فكرة ال Error Correction Code في 1940م بعد ظهور الأجهزة الالكترونية، حيث كانت الأجهزة القديمة غير موثوقة Unreliable ومكوناتها تنتج الكثير من الأخطاء بشكل متكرر، ولكن الاستفادة التي كانت هي في أنظمة الاتصالات والهاتف. وأحد أهم الأحداث التي تسببت في وجودها هي التي كانت في معامل بل للباحث Claude Shannon والباحث Richard Hamming واللذان كانا يعملان في ذلك الوقت في معامل بل. الباحث Hamming كما سبق وتطرقنا له كان سبب اكتشافه لأول أنظمة تصحيح الأخطاء هي انزعاجه من مكوث إجازة اخر الأسبوع في حل لمشاكل فشل الأجهزة Crashes وهذا أدى لظهور Hamming Code.
على أي حال فان ال Error Correction Code هي جزء واحد من فرع يسمى نظرية المعلومات Information Theory، والذي نشأ بواسطة الباحث شانون في ورقته المشهور The Mathematical Theory of Communication في عام 1948م والذي اثبت فيها رياضياً أنه من الممكن من حيث المبدأ تحقيق درجة عالية من الموثوقية بشكل خالي من الأخطاء على وسيط نقل معرض للأخطاء وبه كثير من التشويش، وبعد عدة عقود تمكن العلماء من تحقيق ذلك المعدل الذي وصفه شانون في ورقته.
استخدم Hamming code في الأجهزة القديمة ويستخدم حتى الان في بعض الذواكر Memory Systems، وبعدها أتى نوع مهم اسمه Reed-Solomon code والذي يستطيع تصحيح مجموعه كبيرة من الأخطاء (بالمقارنة مع Hamming Code والذي يستطيع تصحيح خطأ واحد لكل 7 أرقام)، ال Reed-Solomon Code بنى على أساس رياضي Finite Field Algebra ويمكنك ان تقول هو عباره عن Staircase checksum مع ال two-dimensional pinpoint وهو يستخدم في CD، DVD وحتى الأقراص الصلبة Hard drives.
ال Checksums ايضاً له استخدام واسع بشكل عملي (لاكتشاف الأخطاء)، واحد أهم الأمثلة هو في شبكات الايثرنت Ethernet وهو البرتوكول الشبكي الذي يستخدمه أي جهاز حالياً، ال Ethernet يستخدم ال CRC-32 Checksum لاكتشاف الأخطاء، ايضاً بروتكول ال TCP يستخدم ال checksums لكل Packet يقوم بإرساله، والباكتات التي لها checksum خاطئ فهي تهمل لأن ال TCP مصمم لكي يعيد ارساله مجدداً اذا تطلب ذلك.
برامج الحاسب الموجودة على الانترنت ايضاً يتم التحقق منها من خلال checksum، أحد أنواعها المشهورة هي MD5 وSHA-1، وهي لها استخدامات في التشفير، وتستطيع معرفة أي تغيير على البيانات سواء كان كذلك مقصودا أم غير مقصود.
اخيراً، علم ال Error correction وال Error Detection في تقدم، ومنذ 1990 ظهرت طريقة Low-Density Parity-Check وتلقت الكثير من الاهتمام، وهي تستخدم في ال Satellite TV وغيرها من التطبيقات، لذلك المرة القادمة إذا كنت تستمع في قضاء وقتك على المحطات الفضائية في عطلة نهاية الأسبوع، فتذكر أن معركة شانون مع تلك الأجهزة لها دور في ذلك.
من كتاب ” Nine Algorithms That Changed the Future”
سميت بهذا الإسم لأنها تفترض أن النتائج الغير معروفة يمكن تقديرها بالإعتماد على معادلة الخط المستقيم y=mx+b لنفترض أن... التقدير الخطي Linear Regression خوارزميات تعلم الآلة
قياس كفاءة أى خوارزمية أو ادائها يعتمد على عدة عوامل: 1-الوقت CPU (time) 2-الذاكرة memory usage 3- المساحة فى الهارد... التعقيد للخوارزميات Big O Complexity
افترض انك تبحث عن شخص فى دليل التليفون وكان اسمة يبدأ بحرف الكاف (بالطريقة التقليدية) فأنت تبدأ بفتح الدليل وتبحث من... خوارزمية البحث الثنائى Binary search


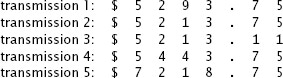



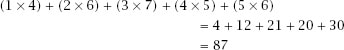



عند سؤال مشابه لهذ ومحتاج لحل
ماهو؟
ممكن الايميل لحضرتك؟
خوارزمية الترتيب الادخال