السلام عليكم و رحمة الله و بركاته

لمن هذه المقالة ؟
هذه المقالة مُوجهة لكل من تعامل سابقا مع أحد توابع الــ RDBMS و لديه إلمام بمعظم مفاهيم الــ advanced databases. الهدف من هذه المقالة هو التعريف بأهمية NoSQL و مقارنتها ببقية الأنظمة المنافسة لها.
الفهرس :
- تعريف
- متى ظهر الزعيم ؟
- ACID و BASE أيهما الأفضل ؟
- أحفاد الزعيم الأربعة
- جولة سريعة مع العملاق الرائع MongoDB
- الخاتمة
1. تعريف
يُمثل NoSQL نمطاً أو نوعاً جديداً من أنظمة إدارة قواعد البيانات (Database Management Systems) حيث يتبع أسلوباً مختلفاً عن الأسلوب التقليدي لقواعد البيانات ذات الجداول المترابطة (Relational Database). من أبرز أوجه الخلاف بين هذين الأسلوبين : الجداول, حيث لا يتخذها NoSQL كوحدة الأساس لبناء قواعد البيانات على عكس الــ Relational Database, لهذا السبب, تستخدم NoSQL لغة UnQL كبديل للغة SQL في التعامل مع البيانات.
لعل أول سؤال يتبادر إلى ذهن القارئ هو : هل أتت NoSQL لتحل محل الــ RDBMS ؟
و الجواب ببساطة : لا !
فقد اختار مؤسسو هذه التقنية الاسم NoSQL كاختصارٍ لـــ Not Only SQL للدلالة على أن هذه التقنية لم تأتِ للقضاء على الــ RDBMS و إنما تُمثل أحد البدائل الـمـُقترحة حيث تُقدم العديد من الحلول خصوصاً في الحالات التي يكون فيها الــ RDBMS عاجزاً عن توفير حلول سهلة, فعالة و مفتوحة المصدر.
أغلب التطبيقات الموزعة (distributed applications) الموجهة للإنترنت (internet-oriented) التي تعمل على قواعد بيانات عملاقة جدا, تستخدم أحد توابع NoSQL لإدارة و تسيير قواعد بياناتها. (انظر الأمثلة الموجودة في الفقرة الرابعة)
2. متى ظهر الزعيم ؟
منذ أربع عقود مضت, أعطى العالم البريطاني المشهور Edgar Frank Codd الضوء الأخضر للأميرة المدللة Relational Database لتدخل قصر قواعد البيانات من أوسع أبوابه. منذ ذلك الوقت, بدأت أميرتنا الصغيرة بفرض سيطرتها في كافة أرجاء القصر, و بعد عشر سنوات من توليها إدارة شؤونه, بدأت حركة الــ Object Database في التمرد بقيادة CPP لتنضم إليها Java في أواخر التسعينات. لكن سرعان ما تدارك الباحثان Christopher J. Date و Hugh Darwen الأمر عندما وقَّعا اتفاق المصالحة المشهور بعنوان البيان الثالث (The Third Manifesto) في عام 1995 و الذي كان من شأنه إعادة روح الثقة بين كلا الطرفين.
بعد ثلاث سنوات من عقد الاتفاق, بدأت الأصوات تتعالى من جديد و السبب هذه المرة هو الغلاء الصارخ لأسعار الـــ DBMS بالإضافة إلى القيود التي تفرضها الرخص التجارية, لذا بدأ وجهاء القصر بالبحث عن زعيم جديد يُمكنه إقناع المحتجين و تلبية طلباتهم مع الحفاظ على الأدوار التي كانت تقوم بها الأميرة المدللة.
في الحادي عشر من حزيران 2009 اجتمع وجهاء القصر بقيادة الحكيم Shashank Tiwari لتجديد البيعة و انتهت الجلسة بتعيين الزعيم NoSQL ملكاً لقصر قواعد البيانات خلفاً للأميرة المدللة. بعد ساعات قليلة من توليه السلطة, عقد الزعيم اجتماعاً طارئاً حضره وكلاء الأسر التي تضررت أثناء حكم الصغيرة المدللة و تكفل بتحمل المسؤولية و إصلاح ما أفسدته الأميرة الصغيرة.
كانت تلك مجرد مقدمة مختصرة أردتُ من خلالها استعراض مختلف مراحل التطور التي مرت بها أنظمة إدارة قواعد البيانات, ابتداء من نشأتها وصولاً إلى يومنا هذا. سنكتفي بهذا القدر من التنظير لننتقل إلى الجانب العملي من هذه المقالة.
3. ACID و BASE أيهما الأفضل ؟
التعامل مع البيانات الحساسة الموجودة في قواعد البيانات يتطلب آلية محددة و دقيقة بحيث تضمن تكامل و تناسق البيانات أثناء إجراء عدة عمليات في آن واحد. يُمثل كل من ACID و BASE فلسفة في التصميم و آلية مختلفة للحفاظ على تكامل البيانات أو اتاحتها حيث يرى BASE أن الأولوية تكون دائما لإتاحة البيانات (availability) وجعلها قابلة للتصفح من طرف مختلف عُقَد النظام بينما يرى نظيره ACID أن الأولوية يجب أن تكون من نصيب تناسق البيانات فيما بينها (consistency) حسب القواعد المـُحددة.
في هذه الفقرة سنتطرق إلى أوجه الخلاف بين هذين الأسلوبين و أيهما الأفضل و متى يكون ذلك ؟
يُعتبر BASE اختصاراً لــ (Basically Available, Soft-state, Eventually-consistent) و يعتمد على الخصائص الثلاث التالية :
- Basically Available : و تعني أن النظام مُتاح بشكل دائم و يمكن الوصول إليه حتى في حالة الــ desynchronization. في هذه الحالة نجد أن الــ availability مضمونة بشكل كامل على عكس الــ consistency لأن النظام سيرد على جميع الطلبات لكن قد يحتوي الرد على بيانات غير متناسقة (inconsistent data) أو يكون الرد مثلا عبارة عن failure.
- Soft-state : تدل هذه الخاصية على أنه يمكن لحالة النظام (state of the system) أن تتغير مع مرور الوقت حتى لو لم تكن هناك بيانات جديدة حيث يُمكن أن تحدث تغييرات في قاعدة البيانات بسبب الــ eventual consistency.
- Eventual consistency : و تعني أن النظام لا يهتم بالـ consistency بعد إجراء transaction معينة لكن في ظرف معين من الزمن و بعد عدد غير محدد من العمليات سيستقر النظام على مجموعة من البيانات المتناسقة و التي تلتزم بالـ consistency rules مع أن هذه الأخيرة هي آخر من يعلم على عكس ما يحدث في ACID.
يُعد ACID من أكبر منافسي BASE حيث يعتمده حالياً معظم الــ SGBD مثل Oracle, SQL Server و Informix. يرتكز ACID على الخصائص الأربع التالية :
- الـ Atomicity : تنص على هذه الخاصية على أن أي transaction إما أن يتم تنفيذها بشكل كامل أو إلغائها بشكل كامل و بالتالي لا توجد half-completed transaction.
- الـ Consistency : كل transaction يجب أن تنقل مجموعة البيانات من حالة متناسقة (consistent state) إلى أخرى مماثلة مع الحفاظ على الـ integrity constraints.
- الـ Isolation : تضمن هذه الخاصية التنفيذ المتزامن لمجموعة من الـ requests في آن واحد حيث يتم تنفيذ كل واحدة بمعزل عن البقية و بالتالي لا يمكن لأي transaction أن تصل إلى transaction أخرى لم يكتمل تنفيذها (أي في حالة الـ unfinished).
- Durability : بمجرد الانتهاء من تنفيذ الـ request بنجاح, لن يتم التراجع عن التعديلات الناجمة عن تلك العملية حتى لو تعطل النظام لاحقاً.
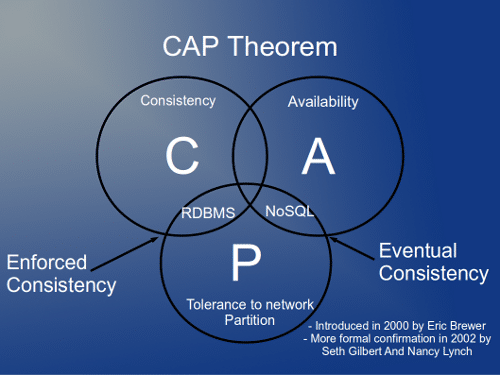
بالنسبة للتطبيقات الموزعة (distributed computer systems) فتنص نظرية Brewer المشهورة باسم CAP Theorem بأنه يمكن فقط ضمان اثنتين من الخصائص الثلاث التالية في نفس الوقت :
- Consistency : في نفس الوقت, تُشاهد كافة عُقَد النظام نفس البيانات.
- Availability : تحصل جميع الطلبات على رد يُوضح نجاح تنفيذ العملية أو عدمه.
- Partition Tolerance : لا يتوقف النظام عن العمل إلا في حالة تعرضه لتعطل كامل, وفي الحالة المعاكسة تظل الشبكات الفرعية تعمل بشكل مستقل.
بشكل عام, عادة ما يبقى الخيار ما بين الــ Availability و الــ Consistency بافتراض وجود الــ Partition Tolerance كخاصية ثابتة في أغلب الأنظمة الموزعة. تُستخدم NoSQL في الغالب في التطبيقات الموزعة التي تلتزم بقواعد ACID و تعتمد أحد خيارات Brewer.
بقي أن نُشير إلى أن NoSQL عادة ما تُستخدم في قواعد البيانات الـمـُوجهة للانترنت.
4. أحفاد الزعيم الأربعة
للزعيم أربعة أحفاد :
4.1 – Key-values Stores
4.1.1 – تعريف : توجد علاقة بين المفتاح و القيمة, تماما كما هو الحال مع جدول هاش (HashMap), القيمة قد تكون سلسلة محارف أو serialized object مثلاً, غياب الــ datatyping في هذا الــ model له تأثيرٌ مهم جداً على الــ Querying لأن التواصل مع قاعدة البيانات سيقتصر على ثلاث عمليات فقط : PUT, GET و DELETE.
4.1.2 – أمثلة :
- Memcached : يقوم بتخزين البيانات فقط في الــ Random-access memory, عندما يتوقف النظام عن العمل يتم فقدان كافة البيانات لذلك يُستخدم عادة لإدارة و تسيير الــ Cache. يعمل على Windows, Linux و Mac OS وهو متوفر برخصة Permissive. ظهر الــ Memcached لأول مرة قبل عشر سنوات من الآن حيث كانت تستخدمه LiveJournal وفي عام 2010 وصل انتشاره إلى عدة مواقع عالمية نذكر منها على سبيل المثال : Orange, Wikipedia, YouTube, Facebook, Twitter.
- Voldemort : تم إصدار أول نسخة منه في 2009 و قد أُخذ اسمه من الشخصية الخيالية للساحر Lord Voldemort في سلسلة Harry Potter المشهورة. تُعتبر النسخة 1.3.0 آخر إصداراته المستقرة حيث لا يزال في تطوير مستمر. اختار Voldemort الثنائي AP من نظرية Brewer. قامت بإنشائه شركة LinkedIn حيث كُتب بلغة Java لذا فهو متعدد المنصات.
- Amazon DynamoDB : توفره شركة Amazon حيث يتبع للفرع الخاص بخدمات الويب, يُعتبر أحد توابع DynamoDB, والفرق بينهما يكمن في اختلاف الــ implementation حيث نجد الأول يعمل حسب أسلوب الــ multi-master بينما يعمل الآخر وفقاً لأسلوب الــ single master. استُخدمت عدة لغات برمجة لكتابة هذا النظام, منها :Java, Node.js, .NET, Perl, PHP, Python و Ruby.
4.2 – Column-Oriented
4.2.1 – تعريف : يُشبه إلى حد ما الجداول الموجودة في الــ RDBMS إلا أن عدد أعمدته ديناميكي على عكس الجداول التقليدية حيث يُمكن وجود عدة records بأعمدة مختلفة مما يسمح لك بتفادى وضع NULL في الخانات الزائدة.
4.2.2 – أمثلة :
- Cassandra : تمت كتابتها بلغة جافا من طرف Facebook حيث أُعلن عن اولى اصداراتها في 2008 لكن سرعان ما تخلى عنها لصالح شركة Apache, تُعتبر الحسناء Cassandra أحد أفراد عائلة الــ BigTable بشهادة العميد Jeff Hammerbacher . تم تصميمها أساسا لإدارة و تسيير قواعد بيانات عملاقة, موزعة على عدة servers مع ضمان اتاحة البيانات بشكل دائم. تحتل الحسناء Cassandra المرتبة 11 من بين أنظمة قواعد البيانات الاكثر استخداماً في العالم, حسب احصائيات موقع DB-Engines. يستخدمها الآن كلٌّ من Twitter, Digg و Reddit بالإضافة إلى الــ Facebook طبعاً.
- HBase : يُمكن من تخزين جداول ضخمة جداً بشكل منظم, كُتب بجافا, متعدد المنصات و متوفر برخصة Apache2.0, ينتمي هو الآخر إلى عائلة الــ BigTable. يُعتبر HBase أحد توابع الــ Hadoop حيث يُستخدم عادة مع HDFS لتسهيل عملية التوزيع لكن مع ذلك كما يُمكن ايضا استخدامه في مجالات أخرى متعددة.
- Apache Accumulo : تم إنشائه عام 2008 من طرف وكالة الامن القومي (NSA) و استولت عليه شركة البرمجيات Apache بعد سنتين من اطلاقه. في 21 آذار 2012 خرج من حضانة Apache لينتقل إلى مستوى أعلى و بعد سنة من تمرده اعلن عن نسخته الجديدة 1.4.3 في الثامن عشر من آذار 2013. يعتمد هذا النظام على تقنية الــ BigTable و يحتل المرتبة الثالثة ضمن أفراد عائلته حسب احصائيات موقع DB-Engines.
4.3 – Document-Oriented
4.3.1 – تعريف : يعتمد هذا الــ model على نموذج الــ Key-values, القيمة في هذه الحالة هي ملف JSON أو XML, الهدف من تمثيل كهذا هو إمكانية الحصول على مجموعة بيانات مرتبة بشكل شجري من خلال مفتاح واحد فقط, نفس العملية تُقابلها مجموعة من الـــ joins في الــ RDBMS التقليدية.
4.3.2 – أمثلة :
- CouchDB : نظام لإدارة قواعد البيانات, مُوجه بشكل خاص إلى تطبيقات الويب, تم إطلاقه في 2005 و بعد ثلاث سنوات, اشترته Apache ليصبح أحد مشاريعها المنافسة على الساحة. كُتب بلغة Erlang, متوفر برخصة Apache. يستخدم ملفات JSON لتخزين البيانات و JavaScript كلغة استعلام تعتمد على خوارزمية MapReduce.
- Couchbase Server : كان يُعرف سابقاً باسم Membase, يسمح بتنفيذ آلاف العمليات في آن واحد كما يضمن اتاحة البيانات لكافة المستخدمين في أي وقت. كُتب بــ C, CPP و Erlang, متعدد المنصات. تم إطلاق آخر نسخة منه في الثالث عشر من أيلول 2013.
- MongoDB : تم اطلاقه في عام 2007 من طرف شركة 10gen حيث اشتُق اسمها من كلمة humongous و تعني عملاق, فعال جداً و لايتطلب مخطط (schema) مُعرف مسبقاً, يستخدم ملفات من نوع BSON لتمثيل البيانات. كُتبت بــ CPP و متوفرة برخصة AGPL. صدرت آخر نسخها في اغسطس 2013.
4.4 – Graph Databases
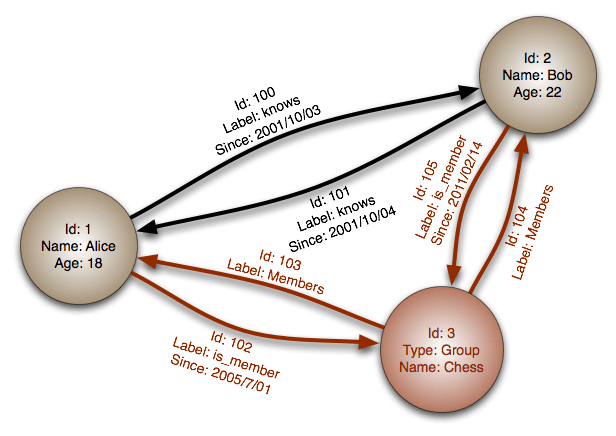
4.4.1 – تعريف : يعتمد هذا الـ model على الــ GraphTheory حيث تحتوي كل عقدة (على الأقل) على مؤشر يحمل عنوان العقدة الموالية و بالتالي لا حاجة في استخدام الــ indexes. يُستخدم هذا النموذج عادة في الشبكات الاجتماعية حيث يسمح بالحصول على معلومات الأعضاء بسرعة, كما يُـمـَكن أيضا من إيجاد العلاقات التي تربط الأعضاء فيما بينهم بشكل سريع جداً (مثلَ إيجادِ أصدقاءِ أصدقاءِ الأصدقاء لعضو معين).
4.4.2 – أمثلة :
- Neo4j : يُعد من أشهر أنظمة قواعد البيانات التي تستخدم الــ graphs, تم إطلاقه في عام 2000 من طرف شركة Neo Technology, كُتب بلغة جافا, متعدد المنصات و متوفر برخصتين هما GPLv3 و AGPLv3. تم الإعلان عن اصدار النسخة 1.0 منه في العاشر من شباط 2010.
- OrientDB : أعلنت شركة Luca Garulli عن أولى نسخه قبل ثلاث سنوات من الآن, يستخدم الــ documents لتخزين البيانات و يعتمد على الــ graphs لربط الملفات بعضها ببعض, يدعم SQL كلغة استعلام كما يدعم على التوالي كلا من schema-less, schema-full بالإضافة إلى schema-mixed. كُتب بالكامل بلغة جافا و قد صدرت آخر نسخة منه في نهاية تموز من العام الحالي.
- InfiniteGraph : كُتبت نواته بـــ CPP و البقية بجافا وهو أحد منتجات شركة Objectivity حيث أعلنت عنه في عام 2010, متعدد المنصات و متوفر بنسختين إحداهما تجارية و الأخرى حرة.
بطبيعة الحال, توجد أنواع أخرى من NoSQL لكنها أقل شهرة مثل ElasticSearch وهو عبارة عن محرك بحث متعدد المنصات يعمل على قاعدة بيانات NoSQL كما توجد أنواع أخرى ربما لم تسمع عنها سابقاً مثل MarkLogic, TokuMX, FleetDB بالإضافة إلى SciDB.
5. جولة سريعة مع العملاق الرائع MongoDB
![]()
5.1 – تعريف : MongoDB عبارة عن نظام لإدارة قواعد البيانات يستخدم ملفات BSON و هي اختصار لــ Binary JSON. يتميز MongoDB بخاصية الــ ShemaLess إذ لا يلتزم بـــ schema معين لذا قد يختلف محتوى الملفات من حين لآخر. يُعتبر Mongo أيضا نظام scalable حيث يُمكنه التأقلم مع آلاف الطلبات في آن واحد دون أن يؤثر ذلك على سرعة الأداء.
5.2 – المميزات
- يُوفر لغة استعلام غنية و مليئة بالدوال الجاهزة.
- يتميز بسرعة الأداء و الكفاءة العالية خصوصاً عند إدخال بيانات ذات حجم كبير جداً باستخدام الـــ batch mode حيث يُمكن إدراج مائة ألف عنصر في الثانية الواحدة.
- يسمح بعمل indexing لخصائص الملفات من أجل تسريع عمليات البحث.
- يُوفر العديد من الدوال التي نجدها في الــ RDBMS التقليدية (مثل count, group by, …) و يُضيف مميزات أخرى متقدمة مثل استخدام سكربتات MapReduce بلغة JavaScript لزيادة سرعة الأداء بالإضافة إلى إمكانية البحث عن بيانات معينة اعتماداً على الــ geolocation.
- القدرة على عمل Replication و Partitioning في عدة instances.
تتكون قواعد بيانات الــ mongo من مجموعة من الــ collections, تحتوي كل collection على عدد غير مُحدد من الـ documents حيث يعتمد حجم الــ collection على عدد الملفات الموجودة داخلها فعند إضافة ملف جديد تتم زيادة الحجم بشكل تلقائي ويتم تقليصه عند حذف أحد الملفات. أحد أهم الفروق بين الــ mongo و قواعد البيانات التقليدية هو أن بنية الملف لا تلتزم بقواعد معينة على عكس الـــ MySQL مثلا, حيث نجد أن مكونات الــ rows هي نفسها في الجدول الواحد إذ يجب أن تخضع لقواعد الــ schema الذي تم تعريفه أما الــ mongo فلا يعتمد أي مخطط و بالتالي يُمكن لبنية الملف أن تتغير من وقت لأخر داخل نفس الــ collection.
ملاحظة : الملفات في الــ mongo تُقابل الصفوف في الــ MySQL.
5.3 – أمثلة على استخدام الــ mongo
المثال التالي يُوضح كيفية الاعلان عن ملفات في الــ mongo :
{
"Nom": "Chikoo",
"Prénom": "Banderas",
"Âge": 23
}
{
"_id": "C04507",
"Nom": "Mohamed",
"Prénom": "AHMED",
"Pays": "Mauritanie",
"Adresse Electronique":
{
"E-mail" : " Snack3R@yahoo.fr",
"Password": " #*MonGoDb-N0$Q!_"
}
}
في هذا المثال لدينا ملفان, يحتوي الأول منهما على 3 حقول بينما يحتوي الثاني على 5, الحقل الأخير يُمثل ملفا حيث يُسمى هذا النوع من التخزين : الملفات المتداخلة أو الــ nested documents.
بالنسبة للمعرف (ID) فيجب دائما أن يكون مسبوقاً بــ underschool, إذا لم نقم بتوفير الــ ID سيقوم الــ mongo بتوليده تلقائيا.
نلاحظ أيضا أن حقول الملفات تتميز بخاصية الـــ strongly-typed إذ لا نحتاج إلى تحديد نوع كل متغير حيث يقوم الــ mongo بتحديد النوع وفقا لمحتوى المتغير.
يُمكنك تحميل الــ mongo من الموقع الخاص به كما يمكنك أيضا تجربة الـــ Shell الـمـُتاح online من خلال الضغط على Try It Out في الواجهة الرئيسية للموقع لتظهر لك واجهة الشل :
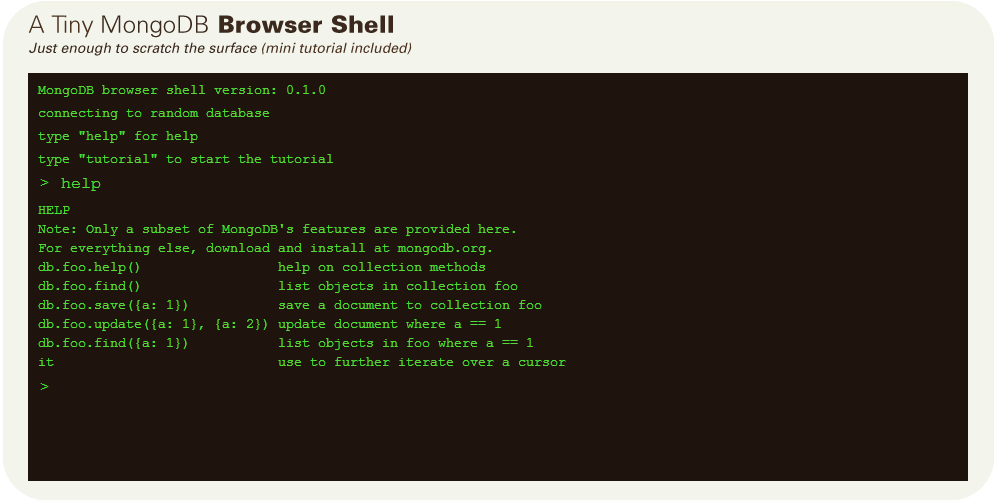
يُمكننا الإعلان عن كائن جديد باسم obj هكذا :
obj = {nom:"Snack3r",age:21};
الآن, obj مُخزن في الذاكرة, عندما نكتب obj ثم نضغط enter سيظهر محتواه. لتخزينه في collection داخل قاعدة البيانات التي نعمل عليها حاليا (عادة ما تكون test بشكل افتراضي) نكتب :
db.collection.save(obj);
الدالة save تُخزن الكائن الممرّر كوسيط داخل الــ collection الـمُستدعاة. إذا كانت الــ collection غير موجودة مُسبقا فسيتم إنشاؤها.
لتغيير قاعدة البيانات نستخدم الأمر use هكذا :
use myDataBase
الآن, قمنا بتخزين الكائن obj داخل collection.
للتأكد من وجوده نستخدم الدالة find بدون وسيط, هكذا :
db.collection.find();
التي تُكافئ
SELECT * FROM table
في MySQL مثلا.
عند إظهار معلومات obj سنحصل على شيء من هذا القبيل :
{ "nom" : "Snack3r", "_id" : { "$oid" : "527f800ccc9374393403c24d" }, "age" : 21 }
لاحظ أنه قد تم توليد ID بشكل تلقائي من طرف الــ mongo.
يُمكننا الاعلان عن كائن جديد مع تحديد الـــ ID :
db.collection.insert({_id:100,nom : "ArabTeam",prenom:"forum",age:13});
و للتأكد من جديد :
db.collection.find();
لاحظ أن محتوى الكائن الثاني يختلف عن الأول لأن الــ mongo لا يلتزم بــ schema محدد.
يُمكننا أيضا البحث عن الكائن الثاني فقط, باستخدام find :
db.collection.find({_id:100});
الكتابة السابقة تُكافئ استخدام WHERE في MySQL مثلا.
تغيير معلومات الكائن يتم باستخدام الدالة update :
db.collection.update({nom:"ArabTeam"},{$set:{age:23}});
تقوم الدالة find بالبحث وفقا لشرط معين على أحد المتغيرات يتم تمريره كوسيط :
db.collection.find({nom:" ArabTeam"})
في هذه الحالة, سنحصل على الكائن الثاني فقط, لكن في الحالة العامة, سنحصل على جميع الكائنات التي تحتوي على حقل nom يُخزن القيمة ArabTeam.
يُمكن أيضا الإعلان عن كائن يحتوي على جدول من الـ strings :
obj2 = {nom:"test",langue:["français","anglais","arabe"]}
لتخزينه :
db.collection.save(obj2);
يُمكننا أيضا الإعلان عن كائن يُخزن داخله كائنا آخر (يُسمى هذا النوع من التخزين, تداخل الكائنات) :
obj3 = {type : obj,option : "yes"};
و لحذف العناصر نستخدم الدالة remove :
db.collection.remove() ;
يُمكن أيضا الحذف وفقا لشروط معينة كما فعلنا سابقا مع find.
توجد العديد من الدوال الأخرى مثل count, drop, sort أترك لك فرصة التعرف عليها بنفسك.
5.4 – توزيع البيانات (Data Distribution)
يدعم الــ mongo نوعين من التوزيع :
- Replica set : حيث يتم استخدام أحد السيرفرات كــ master و الآخرين كــ slaves. في مثل هذا التوزيع, يُنصح دائما بالبدء مع 3 سيرفرات, يتم اختيار أحدهم كسيرفر رئيسي (master) و الاثنان الباقيان كسيرفرات ثانوية (slaves). تُنسخ البيانات الـمُخزنة في الـــ master إلى الـــ slaves بشكل تلقائي و في حالة تعطل السيرفر الرئيسي يتم انتخاب السيرفر الثانوي الذي يحتوي على البيانات الأحدث. السيرفر الرئيسي فقط هو من يمكنه القيام بعمليات القراءة و الكتابة أما الاثنان الباقيان فيُسمح لهم بالقراءة فقط حيث ينحصر دورهم في تخزين البيانات الموجودة في الـــ master خوفاً من ضياعها.
- Sharding : يتم تقسيم قاعدة البيانات لضمان الـــ availability في كل وقت. مفهوم الــ shards يعني مجموعات من الــ replicaset, كل مجموعة تحتوي على جزء من البيانات و الهدف من هذا هو توزيع أو تقسيم المهام بين مختلف الــ replicasets.
6. الخاتمة
في نهاية المطاف, نُذكر مجدداً أن NoSQL لا يُمثل حلا سحرياً لجميع مشاكل قواعد البيانات إذ يظل استخدامه مقتصراً على ميادين معينة و بالتالي يجب على المبرمج إحسان الاختيار مع الأخذ بعين الاعتبار طبيعة الـــ software architecture و تعقيد البرمجة و التطوير في حالات معينة.
في الحقيقة, ما زال الزعيم NoSQL يحتاج إلى اعتراف الــ standards به بشكل أكبر, تماما كما هو الحال مع JDBC و SQL في الــ RDBMS لكن أعتقد أن الوقت ما زال مبكرا فالزعيم لا يزال في ربيع شبابه و أعتقد أن أمامه مستقبل واعد إن حافظ على سرعة الانتشار التي يتقدم بها حالياً.



شكرا جزيلا مقال مفيد
شكرا جزيلا على المقال الهادف والمفيد…بصدد إعداد بحث عن تهجير قواعد البيانات العلائقية ل Nosql..أرغب فالتواصل لتوضيح بعض النقاط
مقال مفيد ومليئ بالمعلومات
جزاك الله خيرا
الحقيقة أنه لايمكن تجاهل روح الداعبة التي امتزجت بالجدية في توصيل المعلومة بشكل واضح وبسيط وسهل على عكس كثير مما قرأت حول قواعد البيانات MongoDB. لك الشكر الجزيل وأتمنى لك مزيدا من التقدم والتطور
انا واجهت مشكلة في استخدام قواعد بيانات mysql وهي انه اوراكل اشترتها منذ عام تقريبا وفرضت قيود على الاستخدام التجاري لالها وانا برمجت سيستم كامل يتعامل معها والان افكر بالانتقال الى MS SQL تمنيت ان اجد بعض اللمحة في هذه المقالة الشيقة عنها
شكر لك
موضوع قديم ولكن اثره باقي
شكرا لك وشكرا حق عبدالعزيز الذي دلني على هذ الموضوع
مقال جميل بس انا اسال من الحجم في الهاردسك مقارنة مع MySQL وشكر