مفهوم ال Single Responsibility Principle واختصاراً SRP هو من أهم المفاهيم في أساسيات تصميم البرمجيات SOLID، وبنى هذا المفهوم اعتماداً على مفاهيم ال Coupling وال Cohesion وال Separation of Concerns والتي سبق أن تحدثنا عنها سابقاً هنا ماذا تعرف عن ال Coupling وال Cohesion في تصميم البرمجيات؟
محتويات السلسلة:
- مقدمة عن ال SOLID
- شرح ال Single Responsibility Principle (المقال الحالي)
- شرح Open/Closed Principle
- شرح Liskov substitution principle
- شرح Interface Segaration
- شرح Dependency Injection
ما هو مفهوم Single Responsibility Principle (اختصاراً SRP)
ينص هذا المفهوم على أنه عليك كتابة أي كود بحيث تكون لديه مهمة واحدة فقط Single Responsibility، لأنه في تلك الحالة سوف يكون له سبب واحد في التغيير:
A class should have only one reason to change
فاذا قمت بكتابة كلاس له العديد من المهام فهذا يعني أنه يوجد أكثر من سبب لكي يتغير هذا الكلاس وبالتالي لم تطبق المفهوم بشكل صحيح، وعليك أن تقوم بتقسيم المهام في ذلك الكلاس الى عدة كلاسات صغيرة ويكون لكل منهم ايضاً مهمة واحدة وبالتالي سبب واحد في التغيير، ونفس الفكرة تنطبق على الدوال ايضاً.
عادة ما يكتب المطورين البرمجيات ويدمجوا جمل الاستعلام والتعامل مع القاعدة مباشرة مع ال View Code سواء كان للويب أو الموبايل أو في تطبيقات سطح المكتب، فسوف تجد داخل زر حدث الدالة أو داخل الصفحة كل الكود الذي يتعامل مع القاعدة ويعالج البيانات حتى يظهرها.
وهذا الأمر يخالف مفهوم ال SRP لأنه يجعل الكود متداخلاً Coupling ويصعب تعديله والصيانة عليه فيما بعد. لذلك مبدأ ال SRP يحاول أن يفصل بين الأشياء التي قد تتغير بنفس السبب مع الأشياء الأخرى التي قد تتغير بسبب آخر.
الصورة التالية تبين نتيجة وضع كل شيء في آن واحد، وليس بسبب أنك تستطيع وضع كل شيء معاً فهذا يعني أنه عليك بالقيام بذلك

لكن ماذا يقصد بمهمة واحدة Single Responsibility؟
الكثير من المبرمجين قد يخطئ ويعتقد أن المهمة الواحدة تعني دالة Method واحدة (أي كل كلاس يجب أن يكون فيه دالة واحدة)، ولكن هذا ليس صحيحاً، والصحيح هو أن الكلاس يجب أن يقوم بمهمة واحدة (بغض عن النظر عن عدد الدوال) لأنه سوف يكون هناك سبب واحد للتغيير.
وأسباب التغيير في المتطلبات عادة تأتي من المسؤولين من البرنامج سواءً صاحب المشروع أو ال Stakeholder المشاركين في المشروع.
مثلاً: تخيل ان تكتب برنامج يقوم بسحب كمية من التغريدات من موقع تويتر وتقوم بعمل خوارزمية ما على هذه التغريدات ومن ثم تقوم بعرضها بطريقة ما على الشاشة، فاذا قمت بدمج كود السحب مع الخوارزمية مع كود العرض في دالة أو كلاس واحد فأنت بهذا الشكل لديك أكثر مهمة وبالتالي أكثر من سبب للتغير، مثلاً يأتي الشخص المختص بالخوارزمية ويريد عمل تغييرات عليها فسوف تقوم بتعديل الكلاس بالرغم من أن الأشياء الأخرى المفروض انها لا تتغير، بنفس المنطق جاء المدير ويريد عرض البيانات بطريقة أخرى وسوف تقوم بالتغيير مجدداً وهكذا.
ونفس الأمر في المثال السابق عندما يضع المبرمجين كل شيء في دالة واحدة، فقد يتم تغيير طريقة التعامل مع القاعدة (أو تغيير نوع القاعدة نفسها) وبالتالي سوف تحتاج أن تغير تلك الصفحة بالرغم من أن التعديل تم على القاعدة، ونفس الأمر يحدث عندما يتم التغيير على طريقة العرض وشكله، أو حتى على سير العمل، فالأشياء الأخرى لا يجب ان تتغير.
قد تقول ما المشكلة في التغيير طالما أن التغير في الجزئية المختصة بالمهمة الأولى داخل الكلاس/الدالة الذي يحتوي على العديد من المهمات؟
والجواب على ذلك أنه بهذه الطريقة سوف تصل الى مرحلة تجد أن الكلاس أصبح متداخل Spaghetti بشكل كبير وأصبح أي تعديل بسيط يكلف وقتاً، بالإضافة الى أن أي مبرمج اخر قد لا يستطيع العمل او فهم هذا الكود، وبالتالي هذا الكود والذي قد يكون جزءاً في برنامج يعمل In Production ولكنه سيء وسيعيق التطور المستقبلي بكل تأكيد.
لذلك دائماً اسأل نفسك بعد أن تكتب أي جزئية من الكود “هل المبرمج التالي الذي سوف ينظر لهذا الكود سوف يفهم بسهولة ماذا يحدث؟”، بالطبع الشخص التالي قد يكون أنت ايضاً

يقول Damian Conway في كتابه Pert Best Practices
عليك أن تبرمج جيداً كما أن الشخص الذي سوف يأتي بعدك مختل عقلياً وهو يعرف أين تسكن
مشكلة الأعتماديات Dependencies
المشكلة الثانية هي في الاعتماديات Dependencies: تخيل لديك كلاس يمثل المستطيل Rectangle ويقوم بعمل مهمتين مختلفتين، الأولى لحساب المساحة Area وذلك عن طريق تطبيق قانون حساب المساحة، والثانية لرسم المستطيل Render وعرضه على الشاشة GUI. فهذا الكلاس سوف يستخدم import/use مكتبات الرسم في اللغة حتى يستطيع عرض المستطيل على الشاشة.
فاذا كانت هناك أجزاء أخرى من التطبيق تعتمد على هذا المستطيل:
- مثلاً لديك جزء Module لرسم الاشكال على الشاشة Graphical Application ويستخدم هذا المستطيل، ولا توجد مشكلة لأن هذا الجزء سوف يحتاج الى دالة حساب المساحة وايضاً لرسم Rendering المستطيل على الشاشة وهذ الجزء بالتأكيد يعتمد على GUI.
- لكن لو كان هناك جزء اخر في البرنامج يقوم بحساب مساحات الاشكال ولا توجد فيه واجهة رسومية Geometry Service، فهو سوف يستخدم المستطيل، ولكن بسبب أن المستطيل يستخدم ال GUI في الدالة render فسوف تجد أن تلك الجزئية التي لا توجد فيها واجهة أصبحت تعتمد على ال GUI هي الأخرى.
الرسم التالي يوضح المشكلة:
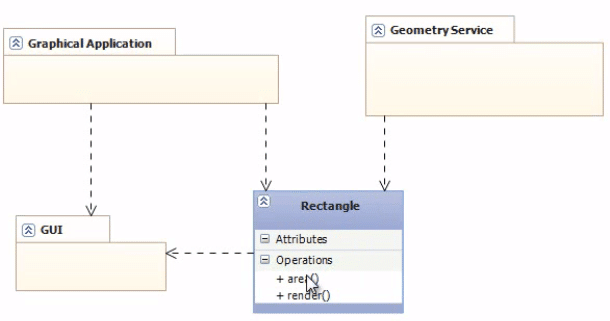
فاذا تم التغيير على ال GUI فهذا يتطلب ايضاً إعادة ترجمة المستطيل وايضاً ال Geometry Service بالرغم من أنها لا علاقة لها بالواجهة الرسومية اطلاقاً. وحل هذه المشكلة يكون عن طريق تقسيم المهام وتطبيق ال SRP فيكون لدينا جزئية تتعلق بحساب المساحة فقط، والأخرى لعرضه على الشاشة، وهنا سوف تعتمد ال Geometry Service على الجزئية الخاصة بالمساحة فقط.
في المثال العملي التالي سوف ترى مشكلة تغيير المتطلبات وكيف أنه سوف يصعب التعامل معها بالكود غير الجيد. وسوف نطرح مشكلة معينة، ولنرى كيف سوف يتجاوب معها المبرمج الذي لا يراعي هذا المفهوم، ومن ثم نقوم بتطبيق المفهوم عليه وسوف ترى الفرق بين الطريقتين بعد ذلك.
مثال عملي على SRP
شركة لديها ملف به بيانات اتصالات الموظفين لشهر معين وتريد حساب التكلفة الاجمالية للموظف وتخزينها في ملف اخر.
الملف يتكون من التركيبة التالية وكل عمود يفصل بينهم بفاصلة (أي Comma Separated Value واختصاراً CSV).
اسم الموظف _ رقم الموظف، تكلفة الرسائل، تكلفة الاتصال، تكلفة الانترنت
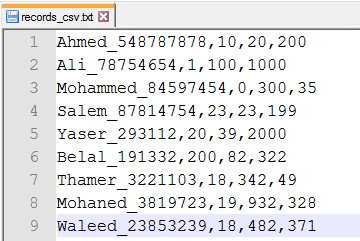
وتريد كتابة برنامج يقوم بحساب التكلفة المطلوبة من كل موظف، ومن ثم اخراج النتيجة في ملف اخر بالصيغة:
اسم الموظف، رقم الموظف، اجمالي التكلفة
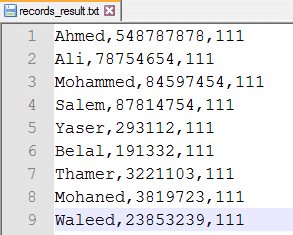
اجمالي التكلفة أعلاه 111 هو مثال وليس التكلفة الصحيحة، ولحساب التكلفة هي مجموع تكلفة الاتصال، والرسائل، والانترنت.
إضافة أخرى في المتطلبات: لقد ذكر لك احياناً هناك بعض الأسطر في الملف المدخل قد لا يحتوي على بيانات صحيحة وانما يجب تجاهله، ويجب قراءة أي مدخل يتكون من 4 أعمدة، وما عدا ذلك يتم تجاهله، ويجب عليك أن تظهر ذلك على الشاشة. الصورة التالية بها 3 أسطر يجب على البرنامج تجاهلها:
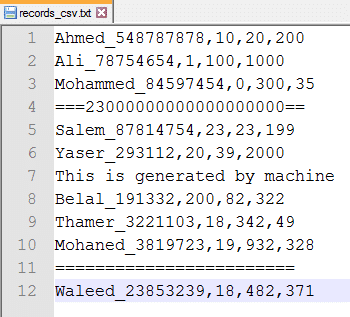
هذه هي المشكلة، وعادة البرامج التي تقوم بأخذ كمية من البيانات وتعالجها أو تخرجها نطلق عليها Batch Processing، مثلاً تأخذ مجلد به مجموعه من الصور تقوم بمعالجة الصور اما بتصغيرهم مثلاً أو وضع علامة مائية عليها، أو مجموعه من البيانات مخزنة على قاعدة معينة تقوم بقراءتهم ومعالجتهم وارجاعهم في قاعدة أخرى أو نفس القاعدة بشكل اخر، فجميعها تقع تحت مفهوم ال Batch Processing، لذلك سوف نطلق على كلاسنا DataProcessor أو EmployeesProcessor.
لتحصل على الفائدة بشكل أكبر يمكنك التوقف هذه اللحظة وتطبيق حل للمشكلة قبل المضي قدماً في قرائة الموضوع.
الحل الأول
لنرى كيف يمكن أن يقوم المبرمج بوضع الحل للمشكلة، وسوف نطبق الحل الان بسي# ولكن حقاً لا يهم ذلك فنحن لن ندخل في تفاصيل اللغة أو حتى ال Syntax فالهدف الان هو ال Design.
public class DataProcessor
{
public void ProcessEmployees(Stream fileStream)
{
// read rows
List<string> lines = new List<string>();
using (var reader = new StreamReader(fileStream))
{
string line;
while ((line = reader.ReadLine()) != null)
{
lines.Add(line);
}
}
// parse employee
List<Employee> employees = new List<Employee>();
int lineCount = 1;
foreach (string line in lines)
{
string[] fields = line.Split(',');
if (fields.Length != 4)
{
Console.WriteLine("WARN: Line {0} malformed, Only {1} field(s) found.",
lineCount, fields.Length);
continue;
}
string[] userParts = fields[0].Split('_');
if (userParts.Length != 2)
{
Console.WriteLine("WARN: User part on line {0} not valid defiention, Only {1} field(s) found.",
lineCount, fields.Length);
continue;
}
decimal smsCost;
if (!decimal.TryParse(fields[1], out smsCost))
{
Console.WriteLine("WARN: SMS on line {0} not valid decimal '{1}'",
lineCount, fields[1]);
continue;
}
decimal mintuesCost;
if (!decimal.TryParse(fields[2], out mintuesCost))
{
Console.WriteLine("WARN: Mintues on line {0} not valid decimal '{1}'",
lineCount, fields[2]);
continue;
}
decimal dataCost;
if (!decimal.TryParse(fields[3], out dataCost))
{
Console.WriteLine("WARN: Data on line {0} not valid decimal '{1}'",
lineCount, fields[3]);
continue;
}
// calculate values
decimal cost = smsCost + mintuesCost + dataCost;
Employee employee = new Employee()
{
Name = userParts[0],
Id = userParts[1],
SMSCost = smsCost,
MintuesCost = mintuesCost,
DataCost = dataCost,
Total = cost
};
employees.Add(employee);
lineCount++;
}
// Store on file
List<string> outputLines = new List<string>();
foreach (var employee in employees)
{
outputLines.Add(string.Format("{0},{1},{2}",
employee.Name, employee.Id, employee.Total));
}
File.WriteAllLines(@"F:\test\records_result.txt", outputLines);
Console.WriteLine("INFO: {0} employees processed", employees.Count);
}
}
كلاس الموظف:
public class Employee
{
public string Name { get; set; }
public string Id { get; set; }
public decimal SMSCost { get; set; }
public decimal MintuesCost { get; set; }
public decimal DataCost { get; set; }
public decimal Total { get; set; }
}
والدالة الرئيسية لتشغيل البرنامج:
class Program
{
static void Main(string[] args)
{
FileStream fs = File.Open(@"F:\test\records_csv.txt", FileMode.Open,
FileAccess.Read, FileShare.None);
new DataProcessor().ProcessEmployees(fs);
Console.ReadKey();
}
}
بعد تشغيل البرنامج سوف تخرج النتيجة وهي صحيحة:
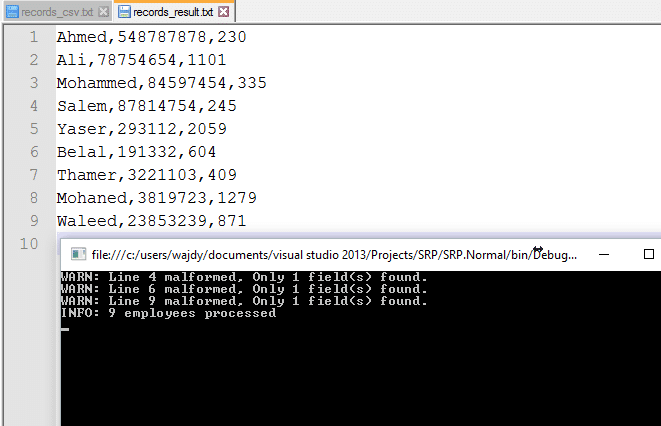
المثال أعلاه هو ليس مثال فقط على كلاس لديه أكثر من مهمة، ولكن في الحقيقة هو مثال على دالة واحدة لديها أكثر من مهمة.
قم بإلقاء نظرة على هذا الكود، وبعد أن تلقى نظره جيدة عليه سوف تجد أن الكود يقوم بعمل الاتي:
- يقوم بقراءة الأسطر من الملف ويضعهم على مجموعه من النصوص list of strings
- يقوم بعمل parse لكل سطر ويستخرج منها البيانات ويضعهم على كائن من الكلاس Employee
- ال parserايضاً يقوم بعمل validationsوعمل Logging على الشاشة السوداء console
- كل كائن Employee سوف يتم وضعه على list بعد عمل فورمات له بشكل CSVومن ثم يتم كتابة البيانات على الملف.
اذاّ لو أمعنت النظر في المهام في الكلاس DataProcessor سوف تجدها بشكل عام:
- القراءة من الملف Streams
- وعمل Parse للنصوص
- عمل ال Validation للحقول
- عمل ال Logging على الشاشة
- الكتابة في الملف
وعلى حسب تعريف ال SRP فإن هذا الكود لا يتبع هذا المفهوم لأنه لديه كثير من المهام وبالتالي الكثير من الأسباب للتغير، وسوف تعرف الان المشكلة الحقيقية في ذلك.
كل شيء جميل ورائع وبرنامجك أصبح يستخدم بواسطة الشركة، ولكن بعد عدة أيام جاءك المسؤول وأراد إضافة بعض التغييرات، وهي كالتالي:
- نريد البرنامج إذا مررنا له القيمة file يضع النتيجة في الملف كما في السابق، وإذا مررنا له القيمة db يضع النتيجة على القاعدة من نوع SQL Server، ولكن في المستقبل يمكن ان نضيف نوع اخر ايضاً.
السؤال الأول: كيف ستتصرف مع هذا التغيير؟
السؤال الثاني: حاول أن تتخيل ماهي الأسباب التي تجعل البرنامج السابق يتغير؟
بالرغم من أن الكود السابق حل المشكلة الأولى، لكن فعلياً في عالم البرمجيات لا يوجد شيء لا يتغير، فكل المتطلبات تتغير وتزداد مع الوقت خصوصاً لو كان للبرنامج قيمة ويخدم مستخدمين بشكل ما.
قد تقوم بعمل الحل، وتقوم بتعديل الدالة ProcessEmployees وجعلها تستقبل بالإضافة الى ال Stream متغير نصي، وفي داخل الكود قبل عملية الكتابة تقوم بالفحص إذا كانت القيمة ملف فاكتب في الملف، وإذا كانت من النوع db فاكتبها في القاعدة. وهكذا تم حل المشكلة بسهولة.
if (type == "file")
{
// Store on file
List<string> outputLines = new List<string>();
foreach (var employee in employees)
{
outputLines.Add(string.Format("{0},{1},{2}",
employee.Name, employee.Id, employee.Total));
}
File.WriteAllLines(@"F:\test\records_result.txt", outputLines);
Console.WriteLine("INFO: {0} employees processed", employees.Count);
}
else if (type == "db")
{
// Open SQL Connection
// Write the data into the databae
// Close the Connection
Console.WriteLine("INFO: {0} employees processed", employees.Count);
}
أو قد تقوم بحل أسوء وهو نسخ الكود كاملاً وعمل كلاس جديد وفقط تغيير الجزئية التي تتعامل مع الكتابة وتغييرها الى قاعدة البيانات. وهذه اسوء من السابقة، لأن أي تغيير في شيء اخر غير الكتابة مثلاً طريقة القراءة من الملف سوف تجبرك على ان تغير في الكلاسين، هذا في حال كنت محظوظ وتذكرت ذلك.
عدة أيام أخرى، ويأتي المسؤول مجدداً ويقول لك نريد أن يقرأ من ملف له صيغة أخرى (غير ال CSV) ويقوم بنفس العملية، أو ملف من نوع آخر مثلاً XML File، وسوف تجد نفسك تقوم بإضافة المزيد من الشروط والتداخل في الكود الى أن يصل الى مرحلة يصعب فيها عمل أي تغيير جديد، أو اصلاح مشكلة ما. وكل ذلك لأن الكود ليس مرن Adaptable بما فيه الكفاية.
لو نظرنا لكود المشكلة، سوف نجد أنه قد يتغير بأي سبب من الأسباب التالية:
- عندما يتغير مصدر البيانات الأصلي من الملف Stream الى مصدر اخر مثلاً يكون من ويب سيرفس Web Service بدلاً من قرائه البيانات من ملف أو مثلاً من قاعدة بيانات ما.
- عندما تتغير شكل البيانات القادمة Data Format مثلاً يتم اضافة حقول اضافية او حذف أي حقل
- عندما تتغير طريقة ال Validation للبيانات
- عندما تتغير طريقة ال Logging مثلاً تتغير من الشاشة الى ملف أو لمكان اخر
- عندما تتغير طريقة التخزين بطريقة أو اخرى، مثلاً غيرت بدلاً من الكتابة في ملف الى قاعدة البيانات العلائقية، أو غيرت الى NoSQL أو حتى سوف تتعامل مع ويب سيرفس وتكون هي الكفيلة بالتعامل مع قاعدة البيانات.
- عندما يتغير سير وتدفق العمل، فالكود السابق يتكون من الخطوات المتسلسلة (قرائه، استخراج، كتابة) وإذا تغير هذه التسلسل فهذا يتطلب التغير ايضاً.
كل هذه الأسباب قد تحدث والكود السابق لا يمكنه ان يصمد بشكل جيد أمام هذه المتطلبات.
انتهى وقت ال Coding وحان وقت ال Design وسنقوم باستدعاء مهندس البرمجيات (الذي يعرف مفهوم ال SRP) لكي يقوم بالتعديل، فبدون تصميم فالكود سوف يصل الى حالة متأخرة للغاية وقد يموت في نقطة ما.
البدء بعملية التصحيح
طالما كل الكود في دالة واحدة في كلاس واحد، سوف نقوم بالشيء المنطقي وهو فصل المهام الى دوال في نفس الكلاس، أي نطبق مفهوم ال SRP على مستوى تلك الدالة الضخمة، وبعد ذلك نرى كيف أصبح شكله والذي يفترض عمله بعد ذلك.
وهذه العملية (نقل الأكواد الى دوال Delegation) هي فعلاً Refactoring لا أكثر.
نقل الأكواد لزيادة المقروئية
سوف نقوم بتقسيم الدالة الكبيرة الى دوال صغيرة كل منها تركز على مهمة واحدة، لو تذكر أن الحل كان عبارة عن 3 أشياء رئيسية هي القراءة من الملف، استخراج البيانات، والكتابة على الملف، ففي هذه الحالة يفترض بعد أن ننقل كل الأكواد ان نخرج بالشكل الجديد التالي للدالة ProcessEmployees:
public void ProcessEmployees(Stream fileStream)
{
IEnumerable<string> lines = ReadEmployeeData(fileStream);
IEnumerable<Employee> employees = ParseEmployees(lines);
StoreEmployees(employees);
}
الآن أصبحت الدالة ProcessEmployees صغيرة بسبب أنها قامت بإسناد Delegate المهام الى الدوال الأخرى.
الكود الأول (الذي كان يحتوى كل شيء في نفس الدالة) كان يقوم بعمل 3 أشياء وهي القراءة من الملف الى نصوص، وتحويل النصوص الى كائنات من Employee وكتابة كل كائن منهم على مكان التخزين. ولاحظ أن هذا الان هو ما يوجد في الكود اعلاه وأن المخرج من كل مهمة تكون مدخل للمهمة التالية فلا تستطيع حفظ الكائنات (دالة StoreEmployees) الا بعد أن يتم عمل ل parse وتحويلهم الى كائنات Employee، ونفس الشيء لا تستطيع استدعاء ParseEmployees الا بعد أن ترجع الاسطر من الملف من خلال ReadEmployeeData.
للنظر الآن لكل دالة على حدة ولنبدأ بالدالة ReadEmployeeData
private IEnumerable<string> ReadEmployeeData(Stream fileStream)
{
var lines = new List<string>();
using (var reader = new StreamReader(fileStream))
{
string line;
while ((line = reader.ReadLine()) != null)
{
lines.Add(line);
}
}
return lines;
}
لاحظ أن الكود لم بتغير وانما وضع على دالة جديدة اسمها ReadEmployeeData وارجعنا الأسطر التي تمت قراءتها في ال IEnumerable<string>. لاحظ هذا يجعل ايضاً الاسطر الراجعة read-only بينما الكود الأول كان يسمح لأي جزئية من الكود بتعديلها واضافة أو حذف أسطر.
الكود التالي يعرض دالة ال ParseEmployees وهي قد تغيرت بعض الشيء وليس كثيراً وذلك بسبب أن الكود الأول كان يحتوى على العديد من الأمور هنا، وقمنا بنفس الطريقة وهي جعل الكود يقوم باستدعاء دوال اخرى للقيام ببعض المهام المساعدة، فتم استدعاء دالة ال ValidateEmployeeData للقيام بعمل ال validation ، ودالة MapEmployeeDataToEmployee لتحويل البيانات الى كائنات Employee ودالة LogMessage للقيام بعملية ال Logging
private IEnumerable<Employee> ParseEmployees(IEnumerable<string> lines)
{
List<Employee> employees = new List<Employee>();
int lineCount = 1;
foreach (string line in lines)
{
string[] fields = line.Split(',');
if (!ValidateEmployeeData(fields, lineCount))
{
continue;
}
Employee employee = MapEmployeeDataToEmployee(fields);
employees.Add(employee);
lineCount++;
}
return employees;
}
كما ذكرنا الدالة قامت بعمل اسناد المهام (مهمة ال validation ومهمة ال mapping) الى دوال أخرى، وبدون هذه ال delegation فسوف تكون الدالة أصعب وايضاً لديها الكثير من الأسباب للتغير.
لنرى الدالة ValidateEmployeeData في الكود التالي حيث ترجع Boolean للدلالة على أنه هل البيانات بالشكل الصحيح أم لا.
private bool ValidateEmployeeData(string[] fields, int lineCount)
{
if (fields.Length != 4)
{
LogMessage("WARN: Line {0} malformed, Only {1} field(s) found.",
lineCount, fields.Length);
return false;
}
string[] userParts = fields[0].Split('_');
if (userParts.Length != 2)
{
LogMessage("WARN: User part on line {0} not valid defiention, Only {1} field(s) found.",
lineCount, fields.Length);
return false;
}
decimal smsCost;
if (!decimal.TryParse(fields[1], out smsCost))
{
LogMessage("WARN: SMS on line {0} not valid decimal '{1}'",
lineCount, fields[1]);
return false;
}
decimal mintuesCost;
if (!decimal.TryParse(fields[2], out mintuesCost))
{
LogMessage("WARN: Mintues on line {0} not valid decimal '{1}'",
lineCount, fields[2]);
return false;
}
decimal dataCost;
if (!decimal.TryParse(fields[3], out dataCost))
{
LogMessage("WARN: Data on line {0} not valid decimal '{1}'",
lineCount, fields[3]);
return false;
}
return true;
}
التغيير الوحيد عن الكود الأصلي هو أن ال validation هنا أصبحت تنادي logging method للقيام بعمل ال logging وذلك بدلاً من القيام بعمل طباعة مباشرة على الشاشة السوداء Console.WriteLine، وهذا يتضح من خلال الكود التالي
private void LogMessage(string message, params object[] args)
{
Console.WriteLine(message, args);
}
لنعود الان الى الدالة ParseEmployees حيث قامت ايضاً بعمل اسناد لمهمة تحويل النصوص من كل سطر في الملف الى كائن من نوع Employee. وهذا يتوضح في المثال رقم 7
private Employee MapEmployeeDataToEmployee(string[] fields)
{
string[] userParts = fields[0].Split('_');
decimal smsCost = decimal.Parse(fields[1]);
decimal mintuesCost = decimal.Parse(fields[2]);
decimal dataCost = decimal.Parse(fields[3]);
decimal cost = smsCost + mintuesCost + dataCost;
Employee employee = new Employee()
{
Name = userParts[0],
Id = userParts[1],
SMSCost = smsCost,
MintuesCost = mintuesCost,
DataCost = dataCost,
Total = cost
};
return employee;
}
الدالة الأخيرة التي تم عملها بواسطة عملية التصحيح Refactoring هذه هي StoreEmployees حيث كما يتبين في الكود التالي تقوم بكتابة ال Employees على الملف، وايضا تستخدم دالة ال Logging.
private void StoreEmployees(IEnumerable<Employee> employees)
{
List<string> outputLines = new List<string>();
foreach (var employee in employees)
{
outputLines.Add(string.Format("{0},{1},{2}",
employee.Name, employee.Id, employee.Total));
}
File.WriteAllLines(@"F:\test\records_result.txt", outputLines);
LogMessage("INFO: {0} employees processed", employees.Count());
}
انتهينا من عمل ال Refactoring وهذه النسخة أكثر وضوحاً من النسخ الأولى من الكود كما لاحظت، ولكن ما هي الأشياء التي استفدنا منها؟
- الدوال أصبحت أكثر وأصغر بدلاً من دالة واحدة كبيرة Monolithic method
- الكود أصبح أكثر مقروئية Readable
- لديك القليل من ال Adaptability حيث يمكن تغيير طريقة عمل الدالة LogMessage وجعلها مثلاً تكتب على ملف بدلاً من الشاشة السوداء، لكن هذا يعني أنك ستغير كود ال DataProcessor لعمل هذا التعديل (وهذا الشيء بالضبط هو الذي نحاول أن نتفاداه من أول هذا الموضوع).
على أية حالة هذه الخطوة الأولى كانت مهمة في وضع حجر الأساس وتمهيد الطريق لفصل المهام بشكل كامل، ما قمنا به حتى الان هو عمل Refactoring ولكن لجعل الكود أوضح for clarity وليس لجعل الكود Adaptable، ونحن الان لدينا كود اجرائي أكثر من كونه كائني.
الخطوة الثانية والتي سنقوم بها هي عمل ال Abstraction المناسب حتى يكون الكود Adaptable (وسوف نقوم بأخذ هذه المهام الصغيرة الى كلاسات ونضعها خلف interfaces حتى نحصل على ال Adaptability المفيدة)
ال Refactoring for Abstraction
سوف نقوم ببناء عدة Abstractions يساعدنا في التعامل مع اي تغيير في المتطلبات، وسوف تلاحظ أن هناك الكثير من الكلاسات الصغيرة وهذا شيء طبيعي. فمن الشائع أن يكون التطبيق صغيراً كما في المثال الأول ولكن بمجرد أن يكون له مستخدمين فسوف يكبر وتضاف له الخصائص، وإذا لم تراعي ال SRP فإن كل الأكواد الجديدة سوف تضاف على القديمة ويزداد تعقيداً مع الوقت كما تحدثنا سابقاً.
عادة تسمى التطبيقات الصغيرة Prototype أو Proof of Concept مثل الكود السابق، والتحويل من تطبيق مصغر الى تطبيق حقيقي Production Product هذا شيء شائع جداً، ولذلك خطوة ال Refactoring toward Abstraction تعتبر مهمة جدا وبدونها قد يكون لديك تطبيق مهم في المستقبل لكنه مكتوب بطريقة سيئة ودوال طويلة فيها الكثير من المهام ويصعب القيام باختبار ذلك الكود وبالتالي سوف يؤثر على مستقبل مشروعك.
سنبدأ العمل الآن، وطالما نحن نعرف ان المشكلة كانت عبارة عن 3 مهام رئيسية هي القراءة من الملف Reading واستخراج البيانات من النصوص Parsing والحفظ في الملف Storing، فسوف نعمم الموضوع، ونقول أننا نريد القراءة بغض النظر عن المكان، وأننا نريد الاستخراج بغض النظر عن شكل البيانات، وأننا نريد الحفظ بغض النظر عن المكان. ولعمل ال Abstraction المناسب لهذه العمليات الثلاثة سوف نستخدم ال interface.
اذاَ سوف نقوم بعمل Interface يمثل عملية القرائة وبالطبع نريده عاماً حتى نستطيع فيما بعد دعم اي نوع جديد، فيمكن أن نسميه IEmployeeDataProvider ووظيفة هذا ال interface هو ارجاع مجموعه من النصوص فقط كما يلي:
public interface IEmployeeDataProvider
{
IEnumerable<string> GetEmployeeData();
}
الان يمكن أن يكون هناك Implementation يطبق هذه ال interface ويرجع البيانات من ملف وممكن بسهولة ان نضيف كلاس اخر يطبق هذه ال interface ويقوم بارجاعها من ملف بصيغة اخرى.
بنفس الطريقة سوف نقوم بعمل ال interface التي تمثل فكرة استخراج الموظفين من هذه البيانات وذلك من خلال IEmployeeParser:
public interface IEmployeeParser
{
IEnumerable<Employee> Parse(IEnumerable<string> lines);
}
واخيراً طريقة الحفظ تكون عامة ايضاً IEmplyeeStorage
public interface IEmployeeStorage
{
void Persist(IEnumerable<Employee> employees);
}
هكذا سوف نخرج بهذا التصميم Design كما في الصورة التالية حيث تبين كيف أصبح الDataProcessor يعتمد على ثلاثة Interfaces
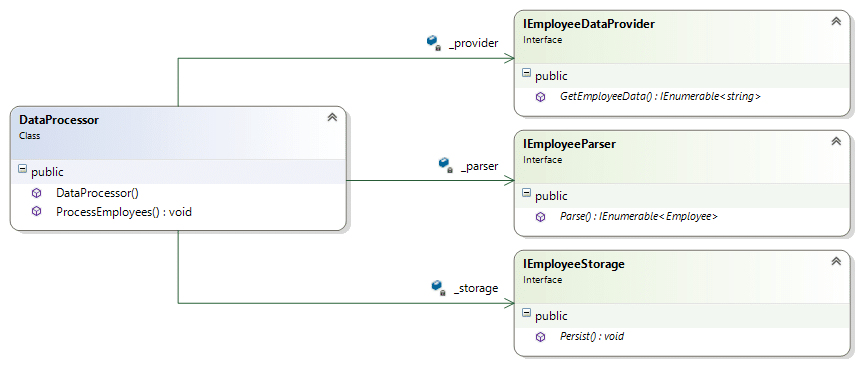
إذا كنت جديداً على موضوع ال Interface وفائدته في البرمجة، فينصحك بقراءة هذا الكتاب العربي “ما هو ال Interface؟” حيث يناقش الكتاب الكثير من الأمور المتعلقة بال Interface وكيف تقوم بعمل Abstraction من خلاله وما هي الفائدة التي تجنيها من خلال استخدامك لل Interface.
لنرى كيف أصبح كود ال DataProcessor بعد ان أصبح يعتمد على ال interfaces:
public class DataProcessor
{
private readonly IEmployeeDataProvider _provider;
private readonly IEmployeeParser _parser;
private readonly IEmployeeStorage _storage;
public DataProcessor(IEmployeeDataProvider provider,
IEmployeeParser parser, IEmployeeStorage storage)
{
_provider = provider;
_parser = parser;
_storage = storage;
}
public void ProcessEmployees()
{
var lines = _provider.GetEmployeeData();
var employees = _parser.Parse(lines);
_storage.Persist(employees);
}
}

لاحظ أن الكلاس قد تغير بشكل كبير عما كان عليه في السابق، حيث أصبح لا يحتوي على اي من تفاصيل طريقة العمل Implementation Details ولكن هو الآن مجرد مخطط Blueprint لسير العملية وهذه هي مسؤولية الكلاس الحقيقية وهو السبب الوحيد الذي قد يتغير هذا الكلاس من أجله.
وأصبح الكلاس هو المتحكم بالعملية مثل ال orchestrate بدون أن يهتم بتفاصيلها.
في حال تغيرت العملية نفسها (الية سير او العمل) فقد يتغير لكن في حال تريد تغيير البيانات المصدر التي تقرأ منها أو طريقة ال Logging أو تريد تغيير طريقة الحفظ فهذا الكلاس سوف يكون كما هو.
لاحظ أيضاً أن ال IEmployeeDataProvider لم يعد يستقبل ال Stream في الدالة، والسبب كما ذكرنا أنه قد تأتي مصادر اخرى للبيانات مثلاً من DatabaseDataProvider أو من ويب سيرفس، وال Stream اصلاً متعلق فقط عندما نتعامل مع الملف، لذلك من المهم جداً ان لا تضع اي اعتمادية عندما تصمم ال Abstraction ويمكنك ان ترسل هذه الاعتمادية Dependency لدالة البناء في الكلاس وبالتالي تستطيع ان تستخدم اي Dependency بدون ان تغير ال Interface، كما يلي في كود StreamEmployeeDataProvider:
public class StreamEmployeeDataProvider: IEmployeeDataProvider
{
private Stream _stream;
public StreamEmployeeDataProvider(Stream stream)
{
_stream = stream;
}
public IEnumerable<string> GetEmployeeData()
{
var lines = new List<string>();
using (var reader = new StreamReader(_stream))
{
string line;
while ((line = reader.ReadLine()) != null)
{
lines.Add(line);
}
}
return lines;
}
}
تذكر ان ال DataProcessor لا يعرف أي شيء سوى GetEmployeeData في ال IEmployeeDataProvider ولا يعرف من ال Implementation الحقيقي الذي سوف يعمل ولا يفترض به أن يعرف ذلك.
بالنسبة لل Parser فهناك الكثير من ال Abstractions التي يمكن استخراجها، تذكر أن التحسين الأول أصبحت الدالة ParseEmployees تقوم بعمل Delegate للمهام (ال Validation وال Mapping) لدوال اخرى، وتستطيع القيام بها الان بشكل أفضل كما يلي حيث تم عمل Refactor لل SimpleEmployeeParser بحيث يكون لكل كلاس مهمة واحدة فقط.
وسنقوم بعمل ال Abstraction المناسب لعملية ال mapping وايضاً لعملية validation حتى ندعم اي تغيير عليهم في المستقبل، ونبدأ بال validator:
public interface IEmployeeValidator
{
bool Validate(string[] fields);
}
وايضاً ال mapper سوف يكون عام هو الآخر:
public interface IEmployeeMapper
{
Employee Map(string[] fields);
}
هذه الطريقة التي قمنا بها (استخراج المهمات الى abstraction ومن ثم كتابة كلاسها تطبقها Abstracting responsibilities into interfaces) هي متكررة Recursive فعندما تفحص اي كلاس وتعرف مسؤولياته فعليك أن تقوم باستخراج المهام Refactor out حتى تبقى المهمة الوحيدة.
الآن اصبح تصميم جزئية ال Parsing كما يلي:
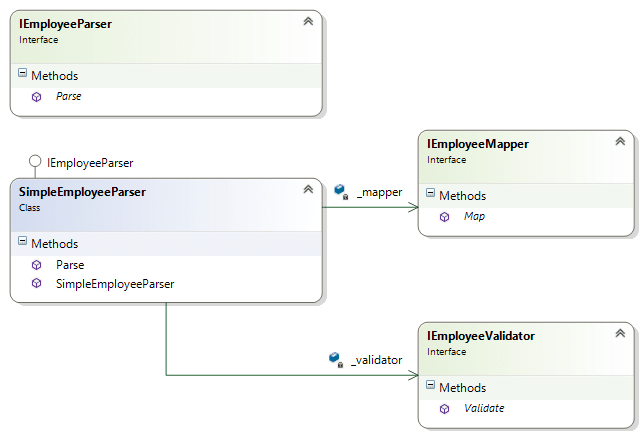
الكلاس التالي SimpleEmployeeParser سوف يطبق اولاً ال interface الخاصة بال Parser، وايضاً سوف يستخدم ال interface الخاصة بعمل ال validations وال Mapping بدون الحاجة الى أن يعرف ما هي طبيعة عمل الكلاس الذي سوف يطبق ال validation وال mapping. وهكذا أصبح هناك سبب واحد فقط لتغيير كلاس ال Parser وهي عندما تتغير شكل البيانات مثلاً من CSV الى مثلاً مفصولة ب tab أو مثلاً XML أو أي شكل اخر.
public class SimpleEmployeeParser: IEmployeeParser
{
private readonly IEmployeeValidator _validator;
private readonly IEmployeeMapper _mapper;
public SimpleEmployeeParser(IEmployeeValidator validator, IEmployeeMapper mapper)
{
_validator = validator;
_mapper = mapper;
}
public IEnumerable<Employee> Parse(IEnumerable<string> lines)
{
List<Employee> employees = new List<Employee>();
int lineCount = 1;
foreach (string line in lines)
{
string[] fields = line.Split(',');
if (!_validator.Validate(fields))
{
continue;
}
Employee employee = _mapper.Map(fields);
employees.Add(employee);
lineCount++;
}
return employees;
}
}
بالنسبة الى ال Mapper فأصبح بعد تطبيق ال interface بالشكل التالي:
public class SimpleEmployeeMapper: IEmployeeMapper
{
public Employee Map(string[] fields)
{
string[] userParts = fields[0].Split('_');
decimal smsCost = decimal.Parse(fields[1]);
decimal mintuesCost = decimal.Parse(fields[2]);
decimal dataCost = decimal.Parse(fields[3]);
decimal cost = smsCost + mintuesCost + dataCost;
Employee employee = new Employee()
{
Name = userParts[0],
Id = userParts[1],
SMSCost = smsCost,
MintuesCost = mintuesCost,
DataCost = dataCost,
Total = cost
};
return employee;
}
}
كود ال Validator أيضاً يطبق ال interface الخاصة بال validation سوف يكون بهذا الشكل
public class SimpleEmployeeValidator: IEmployeeValidator
{
private ILogger _logger;
public SimpleEmployeeValidator(ILogger logger)
{
_logger = logger;
}
public bool Validate(string[] fields)
{
if (fields.Length != 4)
{
_logger.LogWarning("Line malformed, Only {1} field(s) found.", fields.Length);
return false;
}
string[] userParts = fields[0].Split('_');
if (userParts.Length != 2)
{
_logger.LogWarning("User part not valid defiention, Only {1} field(s) found.", fields.Length);
return false;
}
decimal smsCost;
if (!decimal.TryParse(fields[1], out smsCost))
{
_logger.LogWarning("SMS not valid decimal '{1}'", fields[1]);
return false;
}
decimal mintuesCost;
if (!decimal.TryParse(fields[2], out mintuesCost))
{
_logger.LogWarning("Mintues not valid decimal '{1}'", fields[2]);
return false;
}
decimal dataCost;
if (!decimal.TryParse(fields[3], out dataCost))
{
_logger.LogWarning("Data not valid decimal '{1}'", fields[3]);
return false;
}
return true;
}
}
ننظر الان لكيفية التخزين وسوف تكون بنفس الطريقة ونقلها خلف ال abstraction المناسب:
public class FileEmployeeStorage: IEmployeeStorage
{
private ILogger _logger;
public FileEmployeeStorage(ILogger logger)
{
_logger = logger;
}
public void Persist(IEnumerable<Employee> employees)
{
List<string> outputLines = new List<string>();
foreach (var employee in employees)
{
outputLines.Add(string.Format("{0},{1},{2}",
employee.Name, employee.Id, employee.Total));
}
File.WriteAllLines(@"F:\test\records_result.txt", outputLines);
_logger.LogInfo("{0} employees processed", employees.Count());
}
}
انتهينا من كل الكلاسات ما عدا ال Logging، وكما لاحظت اعلاه اننا استخدمنا ايضاً abstraction له بالاسم ILogger كما يلي:
public interface ILogger
{
void LogWarning(string message, params object[] args);
void LogInfo(string message, params object[] args);
void LogError(string message, params object[] args);
}
كل من ال FileEmployeeStorage و ال SimpleEmployeeValidator يعتمدوا على هذا ال Interface ايضاً، ويمكن الان ببساطة عمل ال Implementation الجديد لل ILogger وتكتمل الصورة.
لكن ماذا لو أردنا ان نستخدم أي مكتبة جاهزة لل Logging بدلاً من القيام بأنفسنا، مثلاً مكتبة Log4Net، بالطبع لن نستطيع جعل المكتبة تقوم بعمل Implement لل ILogger لأننا لا نستطيع التعديل عليها، وهنا يأتي دور ال Design Patterns فهي تساعد لحل تلك المشاكل، وال Pattern المناسب الان هو ال Adapter حيث سنقوم بعمل كلاس حول تلك المكتبة كما يلي حيث تبين عمل Adapter للمكتبة Log4Net.
والتصميم التالي يوضح كيف أن كلاس ال Validator وال Storage يعتمدا على ال ILogger وان ال Implementation لل ILogger هو كلاس يستخدم مكتبة اخرى للقيام بذلك.
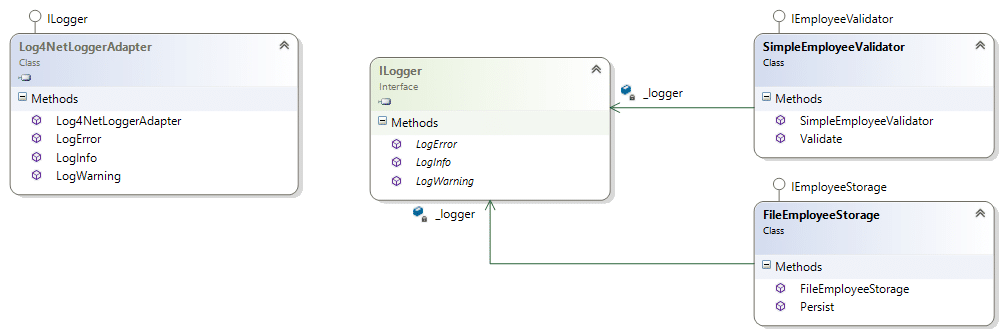
كما تم ذكره في الأعلى أن كل من ال SimpleEmployeeValidator وال FileEmployeeStorage لا يعرفوا الا دوال ال ILogger بغض النظر سواء كان الكود كتبته انت او مكتبة أخرى، وفي نفس الوقت قمت باستخدام مكتبة خارجية، وفيما يلي كود ال Adapter:
public class Log4NetLoggerAdapter : ILogger
{
private ILog _innerLogger;
public Log4NetLoggerAdapter()
{
// initializing
}
public void LogWarning(string message, params object[] args)
{
// log warning
}
public void LogInfo(string message, params object[] args)
{
// log info
}
public void LogError(string message, params object[] args)
{
// log error
}
}
للننظر الان الى الدالة الرئيسية:
class Program
{
static void Main(string[] args)
{
FileStream fs = File.Open(@"F:\test\records_csv.txt", FileMode.Open,
FileAccess.Read, FileShare.None);
IEmployeeDataProvider provider = new StreamEmployeeDataProvider(fs);
ILogger logger = new Log4NetLoggerAdapter();
IEmployeeValidator validator = new SimpleEmployeeValidator(logger);
IEmployeeMapper mapper = new SimpleEmployeeMapper();
IEmployeeParser parser = new SimpleEmployeeParser(validator, mapper);
IEmployeeStorage storage = new FileEmployeeStorage(logger);
DataProcessor processor = new DataProcessor(provider, parser, storage);
processor.ProcessEmployees();
Console.ReadKey();
}
}
وعند تشغيله سوف تجد نفس المخرج السابق بالضبط، فقط مع الاختلاف الكبير بين تصميم الكود الأول وهذا الكود.
نعود لقائمة تغيير المتطلبات التي قد تتغير وسوف نرى ان النسخة الجديدة تسمح لكل منهم بدون تغيير الكلاسات الموجودة:
- طلب: قراءة ال Employees من ويب سيرفس بدلاً من ملف أو Stream؟
- الحل: تستطيع عمل كلاس جديد يطبق IEmployeeDataProvidor ويجلب البيانات من الويب سيرفس
- طلب: شكل البيانات Data Format تغير وتم اضافة حقول جديد؟
- الحل: سوف تعدل على أي كود Implementation يطبق ال IEmployeeValidatorوال IEmployeeMapper وال IEmployeeStorage واضافة الحقل الجديد
- طلب: ال validations rules تغيرت؟
- الحل: سوف تعدل على الكود الذي يطبق ال IEmployeeValidatorوتعدل الشيء الذي تغير
- طلب: تغيير ال Loggin الى ويب سيرفس؟
- الحل من تغيير ال Adapter والذي يستخدم مكتبة Log4Netوالتي بها هذه الخاصية الى النوع الجديد
- طلب: تغيير قاعدة البيانات الى نوع آخر؟
- الحل: يمكن تضيف كود جديد يطبق ال IEmployeeStorageمثلاً ال AdoNetEmployeeStorageأو عمل كلاس مثلاً MongoEmployeeStorage والتي تستخدم MongoDB او حتى كلاس ServiceEmployeeStorage لكي تكتب البيانات في الويب سيرفس.
أعتقد أنك رأيت قوة هذا الأسلوب في العمل وكيف تجعل هناك سبباً واحداً للتغير وذلك يفيدك في جعل الكود أكثر مرونة في العمل المستقبلي وسوف يستطيع تحمل أي تغييرات مستقبلية تطرأ عليه وكل ذلك باتباع خطوتين بسيطة الأولى عمل Refactoring لتبسيط الكود الى دوال صغيرة، ومن ثم عمل Refactoring وضع الكود خلف Interfaces وعمل ال Abstraction المناسب، والاستمرار بعمل هذه الخطوة Aggressive Refactoring حتى تصل الى أي كود لديه سبب واحد في التغيير SRP.
خاتمة
ال SRP له تأثير قوي في Adaptability للكود، وتطبيق ال SRP يولد الكثير من الكلاسات الصغيرة ولها مهمه واحدة فقط، وهو يطبق من خلال Abstraction code خلف Interfaces ومن ثم استخراج المهام غير الضرورية للكلاس للخارج بغض النظر عن ال Implementation الذي سوف يعمل وقت التشغيل.
هناك بعض ال design pattern المناسبة تأتي مساعدة مع SRP وهي ال Adapter Pattern وال Decorator Pattern وسوف يتم تناولهم في مواضع أخرى.
نستطيع القول بأن تطبيق ال SRP يزيد ال Cohesion لأنه يجعل المهام المتعلقة مع بعضها، وفي نفس الوقت يقلل التداخل Coupling لأنه يجعل الأشياء غير المتعلقة مفصولة عن بعضها.
لم نتناول كيف يمكن ان تنشئ هذه الكلاسات وترسل لل DataProcessor من الخارج بشكل أفضل من الموجود في الدالة main الأخيرة، وهذا موضوع منفصل واسمه Dependency Injection والذي لو فوائد عديدة، وكما تلاحظ أن العديد من ال Principles وال Patterns تستخدم مع بعضها لتقديم خلطة جيدة من الكود، وسوف نتحدث عتها في مقالة منفصلة بإذن الله.
المصادر
Adaptive Code via C#: Agile coding with design patterns and SOLID principles
مقالة رائعة جدا
احسنت…جزاك الله خيرا
Good
order androxal cheap melbourne
purchase androxal canada shipping
how to buy enclomiphene uk buy online
cheapest buy enclomiphene no prescription usa
cheapest buy rifaximin australia no prescription
how to buy rifaximin buy dallas
xifaxan overnight without prescription
how to buy xifaxan cheap mastercard
staxyn with next day delivery without prescription with free shipping
buy staxyn for sale usa
buying avodart new zealand buy online
get avodart buy dublin
online order dutasteride no rx needed
ordering dutasteride price australia
buy flexeril cyclobenzaprine toronto canada
cheap flexeril cyclobenzaprine australia buy online
get gabapentin generic health
order gabapentin medication interactions
fildena over the internet
order fildena purchase from canada
ordering itraconazole generic does it work
how to order itraconazole purchase prescription
koupit kamagra dodání
kamagra online bez lékařského předpisu přes noc
générique à bas prix kamagra
acheter kamagra gracieux
R88bet seems to be popping up everywhere. Good odds? Fast payouts? What’s making it so popular? Give me the lowdown! r88bet
U888App seems convenient, downloaded, and ready to test it. Gonna give it a spin and see what all the fuss is about. Link in bio! u888app
Alright guys, let me tell you about rr88slot. Been playing a while now and gotta say, the variety of games is impressive. And the payouts? Let’s just say I’m not complaining! Definitely worth checking out for some reel-spinning fun.
Daily Jili Casino, huh? Daily dose of fun? I’m looking for some new spots. How are the odds here? Tell me everything! dailyjilicasino
Alright 88betag.com, spill the beans. Anyone had any big wins lately? Don’t be shy! I need some motivation. Gotta chase that bread! 88betag.com
F188, heard you’re in the game. Is the platform smooth? Mobile-friendly? Don’t want any lag ruining my winning streak! Thanks in advance. f188