كثير من المبرمجين لديهم نقص في أساسيات مهمه Basic Concepts والذي يؤثر على مدى امكانياتهم لحل المشاكل التي تواجههم بطريقة علمية، بدلاً من التجربة والنسخ واللصق الى ان تحل المشكلة بدون معرفة السبب أو كيف تم حل المشكلة. في هذه السلسلة “ أساسيات لابد لأي مبرمج معرفتها” سوف تتناول مواضيع أساسية لأي مبرمج مثل مواضيع ال Encoding أو ال Time وال Locale والصور Images والألوان Color وأساسيات التشفير Cryptography والضغط Compression وغيرها من الأساسيات المطلوبة لأي مبرمج والتي تجعلك قادر على حل المشاكل بطريقة علمية وممنهجة.
هذا أول موضوع في السلسلة وسوف يتحدث عن 4 أمور مهمه وهي:
- ما هو ال Character Sets وأنواعها مثل ASCII و ال Unicode وما هي ال Encoding وأنواعها مثل الـ UTF-8 والـ UTF-16 والـ UTF-32
- ما هو ال Endianness ولماذا يتم ذكره عند التعامل مع الملفات المرمزة ب Unicode أو عند ارسال أو تخزين الملفات الثنائية Binary Files
- لماذا يجب أن تكون حريصاً عند تعاملك مع الملفات النصية التي تحتوى على ترميز Unicode وما هي العلامة BOM فيها
- طرق أخرى لترميز البيانات في حال وددت ارسال ملفات ثنائية من وسيط لأخر Byte to String
مستوى المقالة / مبتدئ (لا يفترض ان تعرف سوى مبادئ الحاسب Bit, Byte, Binary, Hex, Decimal ).
الفئة المستهدفه/ سواء كنت مطور تطبيقات ويب أو موبايل أو تطبيقات سطح مكتب تتعامل مع اي نوع من الملفات فأنت بحاجه الى قرائه هذه المقالة، وتعلم ال Encoding.
مقدمة عن ال Encoding
أول درس تعلمته في مسيرتك الحاسوبية هي أن الحاسب لا يعرف الا اللغه الثنائية Binary، أي أن كل الصور والملفات و الأرقام و الأحرف التي تكتبها وتراه على الشاشه تخزن بشكل مجموعه من البتات Bits (أي صفر و واحد) في أماكن التخزين Storage سواء كانت في الذاكرة أم القرص.
الدرس الثاني الذي تعلمته هو أنه يصعب التعامل مع الأرقام الثنائية وحفطها بالنسبة لنا البشر لذلك وجدت أنواع التمثيل الأخرى Representations مثلاً النظام السادس عشر Hexadecimal أو النظام الثماني Octal أو النظام العشري Decimal الذي نستخدمه في حياتنا اليومية، وهكذا يمكن أن نمثل الرقم 237 (المكتوب بالنظام العشري) بأكثر من طريقة ففي النظام الثنائي سوف يكون 10011111 أما في النظام السادس عشر سوف يكون 9F أما في ال Octal سوف يكون 159، وكل هذه الطرق تمثل نفس العدد ولكن بتمثيل مختلف ، وفي الغالب نحن نستخدم النظام السادس عشر لأنه مختصر وأسهل من الثنائي.
اذاً عندما تريد تخزين رقم فسواء استخدمت أي طريقة لتمثيله فسوف يتم تخزينه بالشكل الثنائي على الحاسب (الرقم 237 يتم تخزينه 10011111) ، هذا بالنسبة للأرقام ولكي نتعامل مع الأحرف Characters فيجب أن تحولها بشكل أو أخر لأرقام يفهمها الحاسب حتى يخزنها بالنظام الثنائي ، ومن هنا وجدت أول طريقة تحويل Mapping من الأحرف الى الأرقام وهو نظام ال ASCII (نسمية Character Set) حيث هو مجرد اسناد رقم لكل حرف حتى يمكن التعامل معه وهكذا الأمر بالنسبة للأحرف الانجليزية وبعض رموز التحكم Control Characters سيتم اسناد رقم لكل منهم في جدول الأسكي.
في بادئ الأمر كان أي حرف عباره عن 7بت وبالتالي مجمل الحروف التي نستطيع التعامل معها هي 127 (في النظام الثنائي 1111111 وهي تساوي 127)، ولهذا السبب تم تطوير ال Extended ASCII وجعله 8 بت واضافه رموز وأشكال أخرى وهكذا اصبحنا نتعامل مع 256 حرف (في النظام الثنائي 11111111).
جدول الأسكي:
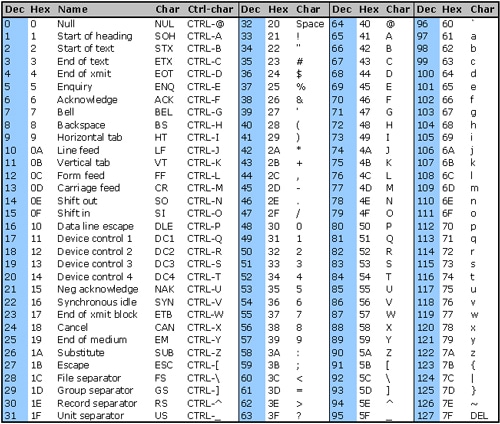
تعريف 1: عمليات تحويل الحرف الى بتات Bits تسمى Encoding Schema واختصاراً نطلق عليها Encoding ، في الجدول أعلاه بعد عمل ASCII Encoding للحرف D الناتج هو القيمة 01000100
تعريف 2: عملية تحويل البتات الى حرف تسمى Decoding وهي العملية العكسية لل Encoding.
تعريف 3: اي مجموعه من الأحرف التي يمكن أن تقوم بعملية Encoding لها نسميها بشكل عام Character Set، أي أن الأحرف هي ال Character Set وعملية تحويلها الى بتات هي Encoding، واختصاراً أي جدول يحتوى على حرف ومقابله سوف تسمى ب Character Set ، اذاً ال ASCII هو Character Set و عملية التحويل فيه تسمى ASCII Encoding.
هذه ال 256 كانت مناسبة في اللغه الانجليزية لكنها لم تكن كافيه لبقية العالم لترميز أحرفهم ولغاتهم، فكان الحل بأن تكون أول 127 حرف هي ثابته كما هو في ال ASCII العادي و ال 128 الباقية تكون للغه التي تريد التعامل معها وسوف تسمى Code Page.
هكذا سنجد لكل لغه Code Page خاصه بها، فاذا استخدمنا ال Code Page للغه العربية (وهو الـ ISO-8859-6 وله اسم اخر في نظام الويندوز وهو Windows-1256 ) سوف نحصل على الأحرف العربية، مثال اذا كان لدينا رقم 200 واستخدمت Code Page عربي فأنني سأحصل على الحرف العربي الذي يقع في تلك الخانه ، وهكذا اذا استخدمت Code Page للغه الصينية سوف تحصل على الحرف الذي يقابل القيمة 200 في ذلك ال ( Code Page في العادة تسمى هذه بال ISO-8859 Encoding ) .
من ال Code Page المشهورة الآخرى (أو ال ISO-8859 Encoding الآخرى ان صح التعبير) هو الـ ISO-8859-1 (أيضاً له اسماء مختلفة مثلاً Latin Alphabet أو ISO Latin ) وكان يستخدم سابقاً في الويب بسبب أنه احتوى على الأحرف الفرنسية والاسبانية

ايضاً هناك Code Page أخريات

ظهرت مشكلة آخرى بعد ذلك وهي أنه توجد هناك لغات لا تكفيها بايت واحد (اي أن ال 128 المتبقة لا تكفيها لأن حروفها أكثر) وبها أحرف أكثر من ذلك البايت ومن هنا طور نظام ال Unicode.
نظام الترميز يونيكود Unicode
صمم هذا النظام Character Set في الأساس على أنه نظام 16 بت (بايتين 2 Byte لكل حرف وليس كالASCII بايت لكل حرف) ، وتم تصميمه بنفس مبدأ وضع رقم لكل حرف كالأسكي (لكن الأرقام هنا في هذا النظام تسمى Code Point).
هكذا أي حرف في اي لغه موجودة تم اسناد رقم ( Code Point ) له (مجال ال Code Point هو من صفر الى أكثر من مليون 1,114,111 حرف، وفي ال Unicode عاده يتم استخدام نظام السادس عشر Hex في الكتابه مع علامه U+ في البدء، وبالتالي مجال ال Code Point هو من U+0000 الى U+10FFFF ).
بما أن ال Unicode في الأساس صمم لكي يكون 16 بت ( يحمل حد أقصى 65536 حرف المجال من U+0000 الى U+FFFF ) فأن اول 16 بت تسمى Basic Multilingual Plane (اختصاراً BMP) والبقية من U+10000 الى U+10FFFF تسمى Supplementary Characters.
وهكذا فأن اي حرف في ال Unicode هو أما يكون في BMP أو يكون Supplementary.
نأتي لنقطة مهمه وهي أن ال Unicode هو مجرد عباره عن أحرف لها Code Point (قيمه عادية) ولكي تستخدمه يجب أن تستخدم ال Encoding له وهو يكون في 3 أشكال UTF-8 و UTF-16 و UTF-32 كل منهم يختلف في ال Code Unit ( ال Code Unit هي عدد البايتات، فمثلاً UTF-8 ال Code Unit لها هو 1 بايت ، بينما UTF-32 فال Code Unit هو 4 بايت).
اذاً لكي تتعامل مع أحرف ال Unicode ونقوم بتخزينها سوف نحتاج لعمل Encoding لها ويكون على أساس الحجم Code Unit (أي التحويل Encoding يكون من Code Point الى واحد أو أكثر Code Unit على حسب ال Encoding المستخدم) ولدينا 3 طرق لعمل Encoding وهي UTF-8 و UTF-16 و UTF-32.
ما الفرق بين هذه ال Encoding ؟
في ال UTF-32 نقوم بتمثيل أي حرف Unicode (أي Code Point) الى Code Unit واحدة فقط، وبما أننا نتعامل مع وحدة 32 بت فاذا أي حرف Unicode يكون عباره عن 4 بايتات وهي بالطبع تأخذ حجماً أكثر من الEncoding الأخرى.
في الUTF-16 تستخدم واحد أو أثنين Code Unit لتمثيل اي Code Point، فالأحرف ال BMP تمثل بCode Unit واحد فقط (وبالتالي تكون 2 بايت فقط) أما الأحرف ال Supplementary تمثل باثنين Code Unit وبالتالي تمثل ب 4 بايتات.
في ال UTF-8 فهي تمثل بواحد الى 4 Code Unit (أي واحد الى 4 بايت) لتمثيل الCode Point، فالمجال من U+0000 الى U+007F يمثل ب 1 بايت، أما المجال من U+0080 الى U+07FF يمثل ب 2 بايت، أما المجال U+0800 الى U+FFFF يمثل ب 3 بايتات ، أما المجال U+10000 الى U+10FFFF يمثل ب 4 بايتات.
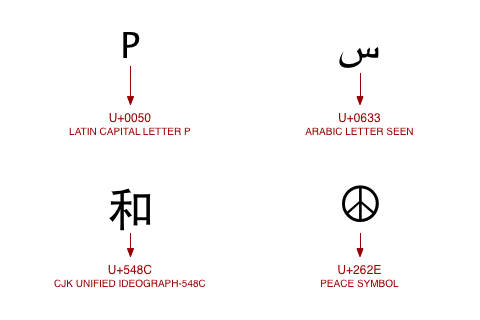
مثال:

الصورة اعلاه احتوت على حرفين BMP :
- دائماً في ال UTF-32 سوف تكون النتيجة 4 بايت
- بما أنه BMP فاذا في ال UTF-16 تكون النتيجة 2 بايت
- في ال UTF-8 بما أن الحرف A يفع في المجال (من U+0000 الى U+007F ) فهو يكون 1 بايت ، ولكن الحرف الأخر يقع ضمن النطاق الذي يرمز ب 3 بايت لذلك هنا سوف يكون 3 بايت.
ميزة ال UTF-8 هي أن الأحرف العادية التي كانت تمثل في ال ASCII بواحد بايت ما زالت تمثل بواحد بايت ولذلك فأنه متوافق Compatible مع ال ASCII.
أغلب تطبيقات الويب ونظام لينوكس يعمل ب UTF-8 فهو الأشهر والأكثر استخداماً, بينما استخدامات ال UTF-16 هي في الجافا والدوت نت والويندوز..
بحكم أن الأحرف العربية هي موجودة ضمن ال BMP ففي الغالب في لغات البرمجة (مثلاً جافا ودوت نت) نستخدم ال String وهو UTF-16 فيكون الحرف الواحد هو 2 بايت ، لكن اذا قمت بجعل البرنامج يدعم اللغات الصيينية واليابانية فأنت تحتاج الى أن تتعامل مع ال Supplementary وكافة اللغات تحتوي دعماً لذلك أيضاً حيث كل حرف يمثل ب 4 بايت في ال UTF-16 لهذه الأحرف Supplementary.
خلاصه ال Unicode هو عباره عن جدول Character Set وتحتاج لاستخدام Encoding لكي تتعامل مع تلك الأحرف، ويجب أن تعلم أن الحرف قد يكون حجمه مختلف بناء على ال Encoding المستخدم.
الفرق بين الملفات النصية Text File والملفات الثنائية Binary File
هناك نوعين من الملفات التي يمكن ان توجد على حاسوبك
- الملفات النصية Text File والتي تحتوى على نصوص بأي لغه كانت
- الملفات الثنائية Binary File والتي لا تحتوى على نصوص (واء كانت صور أو ملفات فيديو أو برامج).
هذه الملفات بنوعيها تكون مخزنة على شكل بتات Bits ، اذاً كيف تفرق بين الملف النصي والملف الثنائي؟
الجواب: على حسب ما تريد أنت (على حسب تفسيرك لها)، اذا قمت بقرائه تلك البتات وقمت بعمل Decode لها على أساس انها ASCII (بالاعتماد على جدول أسكي) فسوف تحصل على الحرف المقابل لكل بايت، فاذا كان تلك البايتات ناتجه عن عملية ASCII Encoding فسوف تحصل على الtext الصحيح ، أما اذا كانت بخلاف ذلك فسوف تحصل على text خاطئ، للتجربة قم بفتح اي ملف ثنائي (صورة مثلاً) من خلال ال Notepad سوف تجد ال text بعد عملية ال decoding على اساس الأسكي.
نظرة حول مفهوم ال Endianness
كل المتغيرات التي توجد في برنامجك تكون مخزنة على الذاكرة، وبما أن هناك بعض أنواع المتغيرات حجمها أكثر من بايت واحد Multi-Bytes فسوف يتم تخزينه في أكثر من slot في الذاكرة بشكل متتابع Contiguous، مثلاً لنفرض أننا في بيئة 32 بت وقمت بعمل int x فلو خزن هذا المتغير في العنوان x0100 فهذا يعني أنه يبدأ من x0100 و 0x101 و 0x102 و 0x103 (لأن المتغير يأخذ 4 بايت).
لنفرض أنك خزنت القيمة 110642547 في هذا المتغير (بالهيكس هي 0x01234567 ) ، فكيف يتم وضع القيم في تلك العنواين؟ هناك طريقتين في ذلك:
- حفظ من البايت الأصغر Least Significant Byte ( الموجود في أقصى اليمين) من أول العنوان في الذاكرة وتسمى هذه الطريقة ب Little Endian وهي التي تستخدم في معالجات Intel والمتوافقه معها.
- حفظ من البايت الأكبر Most Significant Byte ( الموجود في أقصى اليسار) من أول العنوان في الذاكرة، وتسمى ب Big Endian وهي تستخدم في معالجات التي تنتجها IBM, SUN ( هذا يعتمد على المعالج ، فلو انتجت IBM جهاز بمعالج متوافق مع انتل فسوف يكون Little Endian ).

لو رجعنا للمثال السابق بالقيمة 0x01234567 ( فلو كان العنواين تبدأ من اليسار لليمين ) فسوف تكون موجودة هكذا في ال Little Endian تكون القيمة هي 67452301 ، أما في ال Big Endian تكون القيمة هي 01234567.
ربما يتسائل البعض من أين أتت التسمية بهذا الشكل، فهذا يعود الى أحد القصص القديمة حيث تنازعوا في كيفية فتح البيضه، هل من الجزء الكبير Big أم من الجزء الصغير في البيضة Little ، ومن هنا سميت على هذه الواقعه. الجدير بالذكر أنه لا توجد طريقة أفضل من أخرى، والمهم هو في اختيار الاسلوب والالتزام به،
متى ينبغى للمبرمج ان يهتم لهذا الموضوع؟
- في حال كنت تكتب برنامج يرسل binary data من جهاز بمعالج يختلف عن الجهاز الأخر فسوف تحتاج لتوحيد اختيار ال Endianness المستخدم
- ايضاً في كتابه برامج الClient-Server فمثلاً اذا كتبت احدهم بالجافا (وهي تستخدم Big Endian ) والثاني بسي# (وهي تستخدم Little Endian ) فقد ترسل بايتات تصل بشكل معكوس وعليك تحويلها من أحد الأطراف ويجب الاتفاق على طريقة واحدة بين التطبيقين
- عندما تتعامل مع الملفات النصية التي تستخدم UTF-16 أو UTF-32 كما سيتبين ذلك في الفقرة التالية
ما هي علامة ال BOM؟
لماذا يجب أن تكون حريصاً عند تعاملك مع الملفات النصية التي تحتوى على ترميز Unicode وما هي العلامة BOM في هذه الملفات؟

عندما تتعامل مع الملفات النصية أو البرمجية (مثل ملفات XML, PHP, HTML, JAVA فهي ملفات نصية في الأخر) التي تحتوى على نصوص عربية أو أي أحرف غير لاتينية، فعليك حفظ الملف باستخدام ال Unicode حتى تخرج الأحرف صحيحة..
كما ذكرنا قبل قليل، يونكود هو تظام ترميز عياره عن جدول الذي يوضح الحرف وما يقابله من الرقم Code Point وأنه يجب إختيار ال Encoding حتى تستطيع حفظ الملف و هي ثلاثه تراميز UTF-8 و UTF-16 و UTF-32 .
وبما أن ال UTF-16 يرمزوا اي حرف باثنين أو اربعه بايتات ، وفي الUTF-32 يرمز أي حرف ب 4 بايتات ، فان هذه البايتات يجب أن ترتب داخل الملف ، وهناك طريقتين لترتيب البايتات Byte Order (تسمى ال Endianness كما سبق في الفقرة اعلاه) وهي Little endian و Big endian.
هكذا أي ملف Unicode (مرمز ب UTF-16 أو UTF-32) تكون البايتات فيه اما Little endian أو Big endian ، السؤال كيف ستعرف هل الملف من النوع الأول أم الثاني؟
الجواب: عن طريق ال BOM (اختصاراً Byte Order Marks) وهو عباره عن حرف يتم وضعه في أول الملف ولا يظهر عندما تفتح الملف بشكل عادي (فقط في ملفات ال Unicode ) طوله يتراوح من 2 بايت الى 4 بايت على حسب نوع ال Encoding، وهو يوضح لك نقطتين:
- نوع ال Endianness المستخدم (هل هو Big أو Little) ؟
- نوع ال Encoding المستخدم (هل هو UTF-8 أم UTF-16 أم UTF-32)؟
ملفات UTF-8 ليست بحاجه الى توضيح ال Endianness بسبب بسيط الا وهو أن ال Code Unit لها هو بايت واحد وبالتالي لا يوجد داعي لتوضيح الEndianness والسبب أن كل البايتات تكون بنفس الترتيب.
قم بالتجربة الآن، وافتح برنامج المفكرة Notepad في الويندوز ، وقم بحفظ الملف Save AS سوف تجد الخيارات التالية:
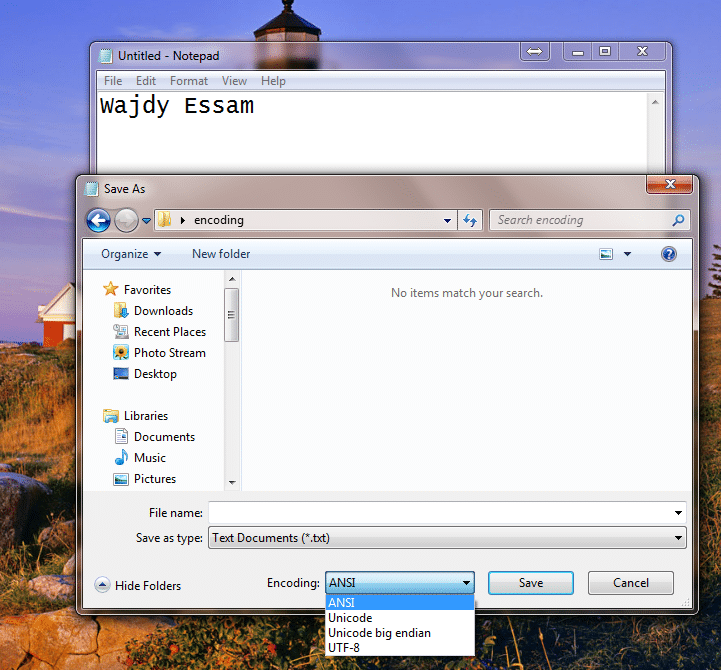
- ANSI وهي لحفظ الملف بالترميز الافتراضي في النظام (على حسب ال Locale اعدادات اللغه لديك)
- Unicode وهو لحفظ الملف ب UTF-16 ( في ويندوز هذا الترميز الاكثر انتشاراً لذلك يطلق عليه هكذا باسم يونكود وهو اسم غير واضح Misleading على اية حال)
- Unicode Big Endian وهو UTF-16 BE فقط
- UTF-8 وهي UTF-8 with BOM ، للأسف لا تتضح كلمة ال BOM هنا، ولكن في غالب برامج ميكروسوفت فهي تضع ال BOM وبرامجها تتوقع أي ملف UTF-8 يحتوي على تلك العلامه وتتجاهلها بعد ذلك، أي هي BOM-aware software.
جرب اكتب اي كود جافا في ذلك الملف وقم بحفظ الملف ب UTF-8 (والذي فيه الBOM)، عندما تشغل المترجم سوف تتفاجئ بالخطأ في السطر الأول
error: illegal character: 187
مترجم الجافا للأسف لا يستطيع التعامل مع الحرف BOM الموجود ولا يستطيع تجاهله، وهناك الكثير من البرامج ايضاً ليست BOM Aware. والحل هو بتغيير ترميز ذلك الملف واستخدام UTF-8 Without BOM، للأسف برنامج Notepad في ويندوز لا يحتوى خيار كهذا ، لذلك ننصح الجميع دائماً باستخدام Notepad++ وتستطيع تغيير ال Encoding بسهوله من قائمة Encoding .
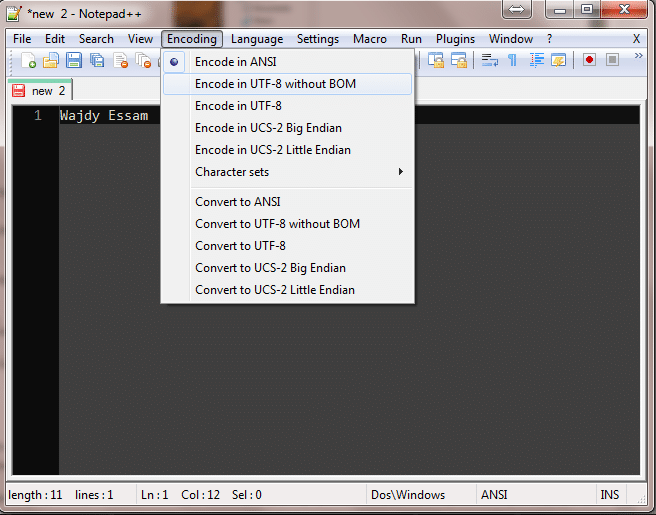
من ناحية أخرى هناك بعض البرامج خصوصاً برامج ميكروسوفت تتوقع ال BOM في اي ملف Unicode، جرب مثلاً قم بعمل ملف فيه Comma Separated Value (اي قيم مفصولة بعلامه فاصلة Comma ) واجعل في بعض الكلمات العربية ثم احفظ الملف بالامتداد csv وافتحه بالأكسل Excel سوف تجد أنه لم يستطيع اخراج الاحرف صحيحة كما هي ، و يمكنك التصحيح من خلال اضافة ال BOM باستخدام ال Notepad++ وتغيير الترميز الى UTF-8 أو من خلال UTF-8 في Notepad والذي يحتوي على BOM في الوضع الطبيعي.
اذاً هناك برامج تتوقع وجود BOM في ملفات ال UTF-8 وهناك برامج لا تتوقع وجودها لذلك حينما تجد أخطاء في أول سطر أو احرف غريبة فتذكر البووم BOM.
يمكن كتطبيق عملي (المشروع رقم واحد في قائمة هذه المشاريع) كتابه برامج يقوم بقرائه اي ملف ويخرج لنا نوع ال Encoding فيه من خلال ال BOM ، ويمكنك ايضاً توفير خاصية لحذف ال BOM ايضاً من الملف..
الفكرة ببساطة، سوف تقرأ الملف كباينري bytes ، وتفحص اول بايتات اذا احتوت على :
- 00 00 FE FF فهذا يعني أنه UTF-32, big-endian
- FF FE 00 00 فهذا يعني أنه UTF-32, little-endian
- FE FF فهذا يعني أنه UTF-16, big-endian
- FF FE فهذا يعني أنه UTF-16, little-endian
- EF BB BF فهذا يعني أنه UTF-8
لكي تحذفها يمكنك عمل Skip لها من المصفوفة، أو كتابتها في في مصفوفة اخرى بدون تلك البيانات ومن ثم تكتبها في الملف مرة أخرى، هكذا سوف يخرج لنا ملف بدون BOM. اذا وجدت ملفات نصية بدون BOM فما زال بامكانك معرفة ال Encoding ولكن الامر يتطلب فحص النص الموجود داخله ومجاله حتى تعرف نوع ال Encoding، لذلك قم بالمهمه في الملفات التي تحتوى على BOM.
طرق أخرى لترميز البيانات في حال وددت ارسال ملفات ثنائية من وسيط لأخر Byte to String
أحياناً قد تريد معاملة الملفات الثنائية على انها ملفات نصية لعده أسباب، مثلاً :
- تريد ان تحفظ الصور في ملف XML ؟
- تريد حفظ الأحرف العربية في ملف لا يقبل الا ASCII ؟
- تريد ارسال ملف في وسيط لا يقبل الا النصوص text-based channel ؟
الجواب :
عن طريق ال Encoding وتحويل هذه البيانات الثنائيه Binary Data أو حتى النصية (فسوف نتعامل على اساس ال Bytes) الى صيغة يمكن ارسال أو تخزين البيانات من خلالها وهي في الغالب US-ASCII ( وهو اي حرف يمكن طباعته Printable تحت ال 127 في جدول الأسكي وهي الأحرف التي ترمز بال سبعة بتات 7-bit ) ، ومن ثم يقوم الطرف الأخر بعد الحصول عليها القيام بال Decode وارجاعها الى شكلها الأصلي الثنائي Binary.
أسهل طريقة لتحويل البايتات لأحرف هي عن تحويلها الى ال Hex Representations، كما نعلم أي بايت يرمز بحرفين في ال Hex ، هكذا لو لدى صورة حجمها 100K وقمت بتحويل البايتات بها الى Hex Digits سوف أحصل على سلسله Hex Digits من 200K (الأحرف التي في السلسه تكون محصورة في ال16 حرف أو رقم من 0-9 و A-F ).
كما تلاحظ طريقة الHex تضاعف حجم Capacity البيانات المرسلة ، وهو أمر يمكن السكوت عنه في حال كانت البيانات صغيرة (كما هو الحال عندما يتم عمل URL Encoding ويتم تحويل الرابط بشكل %DD فهو يستخدم نظام الHex). لكن لا يمكن القيام بذلك في حال كبرت البيانات ، مثلاً تريد ارسال ملف مرفق مع البريد Email Attachment ، فكما هو معلوم انظمة البريد في السابق كانت لا تعمل الا بنظام ال 7- bit اي لا يمكن ارسال الا الأحرف والأرقام والمرموز المطبوعه فقط Printable Character أي ال US-ASCII).
هناك كثير من الأنظمة القديمة ليست 8-bit clean وما زالت تعمل ب 7bit ( نتيجة لذلك وجدت أنواع كثيرة من ال Encoding أشهرها نظام ال Base64 ) نظام ال Hex يسمى أحياناً ب Base16 والسبب ان مجال الأحرف هو 16 التي استطيع الترميز بها، بمعنى كل البايتات سوف تتحول لهذه الاحرف ال 16 ، وبنفس الفكرة ال Base64 مجال الأحرف هو 64 حرف ورقم تتكون من الأرقام العشرة، والأحرف الانجليزية ال26 لل Lower-case وال 26 للUpper-case، وايضاً الاشارات + و / واخيراً الاشاره = والتي تستخدم في حالة كانت هناك Padding.
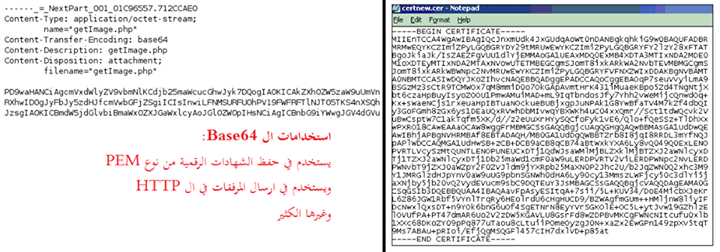
الBase64 يأخذ 3 بايتات من المدخل ويخرج 4 بايتات تكون أحرف مطبوعه ASCII، وبالتالي يمكنك ارسال اي ملف ثنائي لأي وسيط لا يدعم الا ال 7-bit من خلال ال Base64.
مثال بسيط:
الصورة الثنائية احتوت على 3 بايتات هي 155 162 233 نقوم أولاً بأخذ الشكل الثنائي: 100110111010001011101001 ، بعد ذلك سنأخذ كل ستة بتات في مجموعه ، وسيخرج التالي: 100110 سوف تتحول الى 38 ، و 111010 سوف تتحول على 58 ، و 001011 سوف تتحول الى 11، و 101001 سوف تتحول الى 41. وبالرجوع الى جدول Base64 سوف تأخذ الحرف المقابل لكل رقم و سوف تحصل على الأحرف m6Lp، هكذا حصلنا على 3 بايتات والمدخل كان 4 بايتات.
اذاً البيانات ايضاً تزيد حجمها عندما تستخدم Base64 ولكن معدل زيادتها اقل كثيراً من ال Hex. فاذا رجعنا لمثال الصورة 100K فهي تتحول لل Hex ب 200K ولكن في الBase64 تكون 133K. بالنسبة لل Decode فهي العملية العكسية لل Encode وستدخل الأحرف وستحصل على الbinary data كما كانت قبل التحويل.
خلاصة
ال Base64 هو نظام تحويل Encoding يضمن ارسال البيانات بشكل كامل Safe Transportation على اي نظام أو برتوكول لا يدعم 8-bit وهكذا ستضمن ان البيانات تصل بدون اي خراب Data Corruption.
اخيراً، هناك من يخطئ ويقول بأن ال Base64 هو تشفير Encryption وهذا أبعد من الصواب، لأن التشفير يعتمد على كلمة سر أو مفتاح ولا يمكن الحصول على النص الأصلي، أما هنا بمجرد عمل ال Decoding سوف تحصل على الكائن الأصلي!
وصلنا لآخر المقالة ، وأرجوا أن تكون احتوت على معلومات مفيدة للقارئ أو الباحث في علوم الحاسب، اذا كان لديك اي ملاحظة أو اضافة أو سؤال فلا تتردد بالسؤال والمشاركة،



جزيتَ خيراً يا وجدي على المقالة الثرية. استفدتُ منها الكثير.
قرأت المقالة كاملة ولدي بعض الأسئلة:
١. اقتباس
”
في ال UTF-8 فهي تمثل بواحد الى 4 Code Unit (أي واحد الى 4 بايت) لتمثيل الCode Point، فالمجال من U+0000 الى U+007F يمثل ب 1 بايت، أما المجال من U+0080 الى U+07FF يمثل ب 2 بايت
”
لماذا في الـ UTF-8 دائما البت الثامن من أي بايت يكون ٠؟ بمعنى آخر، لماذا لا يكون المجال الأول من U+0000 إلى U+00FF؟
٢. اقتباس
”
متى ينبغى للمبرمج ان يهتم لهذا الموضوع؟
في حال كنت تكتب برنامج يرسل binary data من جهاز بمعالج يختلف عن الجهاز الأخر فسوف تحتاج لتوحيد اختيار ال Endianness المستخدم
”
لو كان البرنامج مكتوب بالجافا، هل اختلاف المعالج سيؤثر على ترتيب البيانات سواء كانت big endian أم little endian؟ باعتبار أن كود الجافا لا يختلف باختلاف النظام، بل الـ JVM هو من يتكفل بذلك.
٣. اقتباس
”
لنفرض أننا في بيئة 32 بت وقمت بعمل int x فلو خزن هذا المتغير في العنوان x0100 فهذا يعني أنه يبدأ من x0100 و 0×101 و 0×102 و 0×103 (لأن المتغير يأخذ 4 بايت)
”
أليست الخانة الواحدة في الذاكرة هي عبارة عن ٣٢ بت في نظام الـ ٣٢ بت؟
ال UTF-8 صمم لكي يكون متوافق تماماً مع ال ASCII وبالتحديد ال 7-bit ASCII لذلك هو يبدأ من صفر وينتهي ل127 كما الأسكي العادي وفي هذه الحالة سوف يكون 1 بايت مثله مثل الأسكي، ما فوق ذلك سوف يكون بأكثر من بايت.
صراحة لا اعلم سبباً لذلك ، ولكن قد يكون بسبب أن ما بعد 127 في الأسكي هي Language Specific وتم دعم كل اللغات في اليونيكود وبالتالي لا يوجد حاجه في دعم البقية حتى 255 لأنها مدعومة Already في code points أخرى. لذلك تم دعم ال127 وهكذا ال UTF-8 اصبح متوافق مع 7-bit أسكي ، وليس ال Extended ASCII (أبو 8 بت).
بالنسبة للجافا فال JVM هي تستخدم دائماً ال Network Byte Order (ال Big) لذلك هي Platform Independent حيث أن الJVM هو المسؤول وليس الOS.
بالنسبة للسؤال الأخر، فالذاكرة مقسمة الى سلسله من البايتات 1 bytes ، لذلك كنا نقول اذا كان المعالج هو 32 بت فانه يستطيع عنونه 4 جيجا بايت فقط (لأن العنواين تبدأ من 1 الى 4294967296) وهكذا لا يستطيع المعالج الوصول لما بعد ذلك.
الان اذا حجزت char سوف تأخذ 1 بايت من هذه السلسلة (في لغه سي مثلاً) واذا حجزت int سوف تحجز 4 بايت (في بيئة 32) وهكذ الأمر لممتغيرات سوف يأخذ عدة بايتات بناء على نوعه، وللمصفوفات ولنقل لديك 10 خانات int (سوف يتم حجز 4 بايت * 10) وبالتالي سيتم حجز 40 خانه متجاورة (40 بايت).
ارجوا ان تتضح الاجابات لديك ، والا سأحاول الاجابه مجددأ عليها،،
أسئلة جميلة للغايه فواد ، لك التحية 🙂
موضوع أكثر من رائع وأضاف لي الكثير بصراحه, جزاك الله خيرا وجدي.
معلومات جدا مفيده ،، جُزيت خيرا ولك جزيل الشكر
مقال رائع … قليل جدا هم من يهتمون بالتفاصيل و بالفهم العميق للامور بدلا من القص و اللزق
انا بعد قراءة المقال عندى شوية اساله لو حضرتك تجاوبنى عليها
1 – انا بعمل encode لل data اللى عندى بطريقة معينة علشان ارجعها للصيغتها الاصلية لازم اعملها decode بنفس الطريق ؟؟
2- اذاكنت هبعت رساله عربية من ابلكيشن جافا لرقم موبايل ليه املها encoding مداه ال موبايلل مش هيعملها decoding و ليه لو معملتهاش encoding بتظهر question marks
هي الداتا في الأساس تكون عباره عن مجموعه من البايتات فانت تستخدم ال encoding عشان تظهر تلك البايتات بالشكل الصحيح، اما الdecoding فهي لك تحصل على البايتات من النص الذي لديك.
فانت لم ترسل بيانات فتعملها deocding وترسل في مصفوفة بايتات ، والطرف الأخر هو اللى يفسرها باستخدام ال encoding لكي تظهر له بالشكل الصحيح.
ارجوا ان أكون فهمت سؤالك وأجبت عليه بالشكل الصحيح.
وشكراً.
كيف يتم تمثيل اكثر من مليون حرف باستخدام 16 بت !!!
4fd9c13b a25a9dae c83c0665 df1ac9f8
لو سمحت السابق كود لون كيف يمكن تحويله الى rgb
ربما كان ناتجاً من تشفير لذلك قد لا يمكن تحويله بالسهولة.
من اين حصلت عليه؟ يمكنك عمل تحليل عكسي للبرنامج الذي يقوم بالتعامل معه ومعرفة الطريقة.
وشكراً.
لو سمحت بدي معلومات عن الترميز1- ترميز BCD
2- ترميز غري Gray code
3- الترميز الحرف- رقمي Alphanumeric Codes
4- الترميز أسكي ASCII Code
اذا بتريد ضروري جدا وبدي محاسن ومساوئ كل منن ضروررررري
انت أكيد من الجامعة الافتراضيه وعندك وظيفة GDE101 هههه انا عم دور عنفس الموضوع
marwa بتاريخ 29 نوفمبر,2016 – 9:53 م
لو سمحت بدي معلومات عن الترميز1- ترميز BCD
2- ترميز غري Gray code
3- الترميز الحرف- رقمي Alphanumeric Codes
4- الترميز أسكي ASCII Code
اذا بتريد ضروري جدا وبدي محاسن ومساوئ كل منن ضروررررري
الافتراضية السورية كلا هون هههههههههه
ههههه ألعن ابو هالوظيفة فضحتونا
اذا لقيتوا شي خبروني ^^ لان برجع وبلف ع نفس الموقع
هههههه يا شباب طبع شي معكن
جزاك الله الف خير،
دائماً ما يتعبني موضوع الترميز والان شرحت لي الكثير وفهمت الكثير لكن لا يزال هناك بعض الاشياء لم افهمها لان ليس لدي خلفية كبيرة في الموضوع، هل تقترح بعض الكتب التي تسهل الامر او ربما تغطي بعض الخلفيات التي فاتتني، وشكراً 🙂
يا شلاب البد الافتراضية كلها هين خههههههه
شلاب البدو قصدي ههخخخخخخخخخخخ
أنا كمان هون منشان الوظيفة GDE101 ههههه
طيب ممكن اعرف في الاسكي كيف اجد الترميز للحروف العربية
انا عاملة كود بحيث ما يسمح الا بادخال الارقام من 48 ل 57 عاوزة نفس الكود ولكن للحروف العربية
اخي الكريم
الان يوجد لدي ملفات بامتداد Dat واريد فتحها وقرائتها للتعديل عليها كيف يمكني فتحها وبأي برنامج وخاصة انها تظهر بهذا الشكل ان فتحتها على برنامج النوت او اي محرر اخر نوت باد++
———————————————————————–
×>tà0k=ïLغV•¥îCق—èƒ qè:وٍ¤÷xƒ؛èؤجدç«ثد w™JشR6.ضâ’oSڈزjّثه>گئJ›“Wمr_ي,¨ذ¨,«™g|‡ـ/{SwPc’N¸‰¨NqüL،{5ےRsجژlv`’P^¬§إI…`
—————————————————————————-
أول مرة اشوف موضوع شامل ومشروح بالتفاصيل دي كلها وبكمية الامثلة دي كلها … انت عااااااالمي
_______
almogtama3.com
أشكرك موضوع متميز جدا ومهم لك مني التقدير
جزاك الله خير مقال رائع رائع
الله يجعلها في ميزان حسناتك و يبعد عنك كل الشر، لقد حصلت على معلومات مفيدة لم أحصل عليها في الجامعة…
استاذ السلام عليكم لو سمحت انا مهتم بالترميز بصفه عامه وبحاول اتابع اى مقاله او معلومه بس عندى ملف مش عارف اعمله Decoding فلو سمحت ممكن تساعدنى فيه
السلام عليكم
عندي ملف notepad
كان به نصوص عربي وكان شغال تمام علي ويندوز 7
لما استخدمت وندوز 10 اصبح رموز غريبة
هل يمكن استعادة النص العربي ؟
جربت احول الملف ل utf 8
ولم يعمل وكذلك اضفت اللغة العربية والموقع وايضا لم يتم
مع العلم الملفات الجديدة تحفظ بالعربي بشكل طبيعي
upvote()
ممتاز