العديد من البرامج التي نستخدمها بشكل يومي تستخدم خوارزميات سريعة في البحث قد لا ندري عنها، فبدئاً من محرك البحث في على الويب Google أو MSN Search والتي تخرج لك النتائج في غضون ثانية واحدة وأيضا برامج البحث في نظام التشغيل لديك Desktop Search Engine والتي تبحث في الملفات الموجودة لديك على النظام وتخرج لك نتيجة بسرعة جيدة ، وإنتهائاً ببرامج البحث في التفاسير والمعاجم وفي ارشيف المكتبات ، وغيرها كثير من التطبيقات تتطلب الحصول على النتيجة في اسرع وقت ممكن..
هذه الخوارزميات نتطوي تحت مجال كبير يسمى Information Retrieval (اختصارا IR) وهو يهدف للبحث عن المعلومات سواء داخل الملفات أو البحث عن الملفات نفسها والبحث في شبكة الانترنت World Wide Web وأيضا البحث داخل قواعد البيانات العلائقية RBDMS، وأشهر الأمثله على الIR هي محركات البحث في الويب Web Search Engine.
الفكرة من وراء السرعة في جميع تلك البرامج ومحركات البحث هي ال index ، فعند بناء للIndex تستطيع من خلاله الوصول لما تريد من الملفات التي قمت بعمل index لها بسرعه كبيرة، لنأخذ مثالا في الحياة اليومية على استخدام الindex، فعندما تريد البحث عن كلمة معينه داخل كتاب ورقي كبير مكون من 1000 صفحة، فهل ستقوم بالبحث سطر بسطر من أول صفحة في الكتاب آخر صفحة؟ بالطبع حل غير عملي.. ولكنك يمكنك الحصول على الصفحة التي وجدت فيها هذه الكلمة من خلال ال index الموجود في نهاية كل كتاب.
هكذا اذا أردت البحث عن كلمة Ant ستنتقل الى الصفحة التي تحتوي جميع الكلمات التي بدأت بالحرف A ، وبنظره سريعه ستجد الكلمة Ant والصفحات التي تتكررت فيها، فهنيئاً لك .
الindex في عالم الحوسبة لا يختلف كثيرا عن index الموجود في الكتب، فهو أيضا يتكون من جميع الكلمات التي تتكررت وعدد تكرارها والمسارات التي تتكرت فيها تلك الكلمات، وبالتالي عند بحثك على الكلمة فسوف تخرج لك مباشره النتيجة عن طريق البحث في الجدول الذي يحتوي على الكلمة واستخراج الموقع الذي وجدت فيه تلك الكلمة.. الجميل في الcomputer indexing هو في أنك يمكنك تخزين أي معلومات تريدها في الindex وليس فقط مسار الملف، يمكنك تخزين معلومات الملف metadata ، يمكنك تخزين حجمه size والامتداد وأي معلومات تريدها.. وسوف تستفيد من ذلك حتما في البحث، حيث يمكنك البحث عن الملفات التي ألفها محمد بالامتداد txt والتي احتوت كلمها سي++ في التاريخ ما بين 2004 الى 2006 ، استعلام جميل أليس كذلك! وسوف تحصل على نتائج سريعة جدا ربما أقل من نصف ثانية!
تركيبة الindex هي ما تجعل التطبيقات الأخرى قابلة للبحث فيه بكل سرعه، لحسن الحظ أو سوء الحظ (تختلف باختلاف حالتك) لن نتطرق هنا الى بناء هذه الdata structure ولا تفاصيلها، ولكن سنقوم بالاستفاده من جميع خصائصها من خلال المكتبة Lucene، وقتا ممتعاً .
ما هي Lucene ؟
هي مكتبة IR عالية الأداء، مفتوحة المصدر، من خلالها تستطيع اضافة خاصية البحث السريع لبرامجك ، بدأت كغيرها في من المشاريع على sourceforge وانتهت أيضا كغيرها من المشاريع القوية تحت مظلة Apache Software Foundation والتي لا تألوا جهدا في ضم أي مشروع تحت لوائها تتشم فيه رائحة التميز . Lucene (وهي اسم زوجة مبرمج المكتبة Doug Cutting والأخير معروف بخبرته في مجال الIR عموما، حاليا اطلق أول محرك بحث مفتوح المصدر Nutch لا تتفاجئ حين تعرف ان المحرك يستخدم لوسين أيضا  ).
).
كما في بقية المكتبات فإن Lucene تقدم لك Abstraction جيد في عملية الindexing والSearching وتقدم لك API سهله الاستخدام، هذا الAbstraction يعني أنه بامكانك استخدام lucene في برامجك بدون أن تكون لديك معرفة بألية عمل الindexing والsearching وسوف تحصل على أداء عالي منها.
العديد من المشاريع كتبت بالاعتماد على lucene منها Nutch و SearchBox و jSearch وغيرها الكثير الكثير والقائمة طويلة:
http://wiki.apache.o…-java/PoweredBy
اضافة للعديد من الporting للغات الأخرى ، فسوف تستطيع استخدام lucene الان اذ كنت مبرمج java , C++, .NET, python , Perl .الجميل في الأمر انك تستطيع الوصول لindex كتب بلغة أخرى من خلال لغتك المختلفة عن اللغة التي كتب بها الIndex.
الصورة التالية توضح عن كيف سيتفاعل تطبيقك مع lucene.
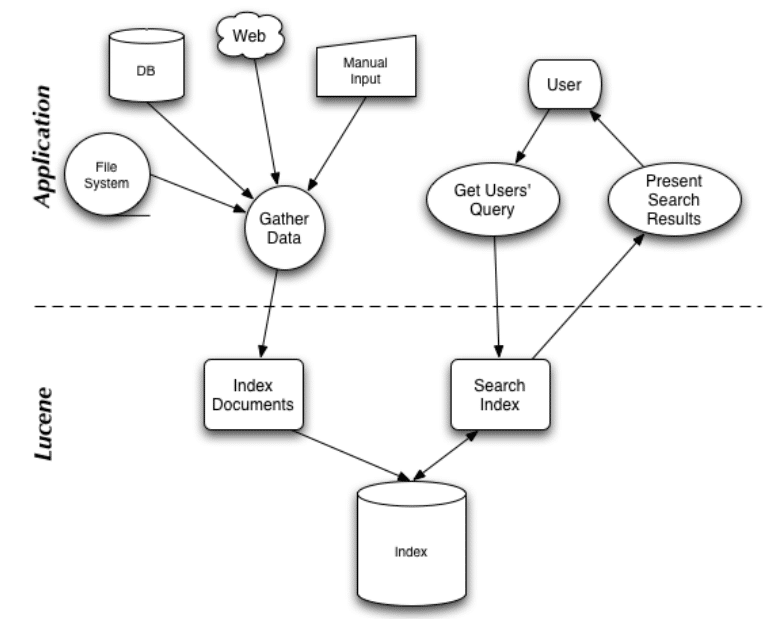
كما هو من الصورة فانك تستطيع ان تقوم بعمل Index للملفات من جهازك أو بيانات مدخله من المستخدم أو صفحة ويب أو حتى قاعدة بيانات وبعد ذلك يمكنك البحث عنها بالطريقة التي تريد، حيث تدعم lucene استعلامات متقدمة سواء بالعلامات المنطقية and or أو حتى باستبعاد كلمة معينة من خلال – + وغيرها من أنواع البحث مثلا Fuzzy Search.
لكن يجب ملاحظة أن جميع ما يمكن وضعه في الindex يجب أن يكون على صيغه نصوص Textual information، واذا أردت عمل index لملفات بصيغة ثنائية مثلا pfd, word, pst, ppt يجب ان تقوم باستخراج النصوص من الملف أولا بنفسك (Lucene لن تقوم بعمل parsing لك) وبعدها يمكنك ان تدخله في الindex . أيضا ملفات الhtml عليك باستخراج النصوص من الtags اذا أردت أن يكون البحث من خلال النصوص داخل الtags (بمعنى تستخدم html parser لكي تستخرج النصوص).. وهكذا لجميع الصيغ عليك أن تستخدم parser مناسب من خلال تحصل على الtextual information حتى تضعه داخل الindex.
لنأخذ مثال على البحث في جميع الملفات النصية txt داخل القرص G ، قم أولا بتحميل lucene وضع ملف الjar في مسارك الذي تعمل عليه، ثم شغل البرنامج التالي:
// indexer example in java lucene
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import java.io.File;
import java.io.IOException;
import java.io.FileReader;
import java.util.Date;
public class Indexer {
public static void main (String[] args) {
try {
if (args.length != 2 ) {
System.out.println("error in usage , use : java Indexer <indexDir> <dataDir>");
return ;
}
File indexDir = new File(args[0]);
File dataDir = new File(args[1]);
long start = new Date().getTime();
int numIndexed = index(indexDir, dataDir);
long end = new Date().getTime();
System.out.println("Indexing : " + numIndexed + " take : " + ( end-start ) + " Millisecond(s)");
}
catch (IOException e) {
e.printStackTrace();
}
}
public static int index (File indexDir , File dataDir) throws IOException {
if ( !dataDir.exists() || !indexDir.exists() )
throw new IOException("not found one of the arguments");
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(), true);
writer.setUseCompoundFile(false);
indexDirectory(writer, dataDir);
int numIndexed = writer.docCount();
writer.optimize();
writer.close();
return (numIndexed);
}
public static void indexDirectory(IndexWriter writer, File indexDir) throws IOException {
File[] files = indexDir.listFiles();
if ( files != null ) {
for (int i=0 ; i<files.length ; i++) {
File f = files[i];
if ( f.isDirectory() ) {
indexDirectory(writer,f);
}
else if ( f.getName().endsWith(".txt") ){
indexFile(writer,f);
}
}
}
}
public static void indexFile (IndexWriter writer, File f ) throws IOException{
if ( f.isHidden() || !f.exists() || !f.canRead() )
return ;
System.out.println("indexing: " + f.getCanonicalPath());
Document doc = new Document();
doc.add(Field.Text("contents", new FileReader(f)));
doc.add(Field.Keyword("filename", f.getCanonicalPath()));
writer.addDocument(doc);
}
}
لاحظ عليك تمرير قيمتين للبرنامج الأولى المجلد الذي سيحتوي على الindex ، والثاني على مسار المجلد الذي تود عمل indexing له حتى تستطيع البحث فيه ، عن نفسي نفذت الأمر:
java indexer I:\muindex G:\
هكذا سيتم عمل index للقرص G ويتم وضع تلك البيانات في I:\myindex .
بعد انتهائك من عمل الindex والتي قد تأخذ وقتا طويلا (هذا يعتمد على حجم الملفات التي تود عمل index لها ) ولكنها ستكون بالطبع لمرة واحدة هذه العملية.. بالنسبة لي انتهت عملية البحث في 6010 ميلي ثانية ل76 ملف نصي.
بالرغم من أن عملية الIndex طويلة نوعا ما (لكن قد تسرع باستخدام أكثر من thread) ، الا أن عملية البحث تكون سريعه للغاية ، شغل المثال التالي لكي تقوم بالبحث:
// Searcher in Index Files
import org.apache.lucene.document.Document;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.Hits;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.Directory;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import java.io.File ;
import java.util.Date;
public class Searcher {
public static void main (String[] args) throws Exception {
try {
if ( args.length != 2 ) {
System.out.println("error in usage , use: java Searcher indexDir QueryString");
return ;
}
}
catch(Exception e){
e.printStackTrace();
}
File indexDir = new File(args[0]);
String queryString = args[1];
if ( !indexDir.exists() || !indexDir.isDirectory() )
throw new Exception("directory is not found");
search(indexDir,queryString);
}
public static void search (File indexDir , String queryString) throws Exception {
Directory fsDir = FSDirectory.getDirectory(indexDir, false);
IndexSearcher is = new IndexSearcher(fsDir);
Query query = QueryParser.parse(queryString,"contents", new StandardAnalyzer());
long start = new Date().getTime();
Hits hits = is.search(query);
long end = new Date().getTime();
System.out.println("Found: " + hits.length() + " document(s) (in " + (end-start) + " Millisecond(s) ) that matched Query"
+ " '" + queryString + "':");
for (int i=0 ; i<hits.length() ; i++){
Document doc = hits.doc(i);
System.out.println( doc.get("filename") );
}
}
}
عليك بتمرير معاملين للدالة main ، الاولى مكان الindex والاخرى الكلمة التي تريد البحث عنها ولاحظ النتيجة تكون سريعه جدا، في تجربتي استغرقت 6 ميلي ثانية:
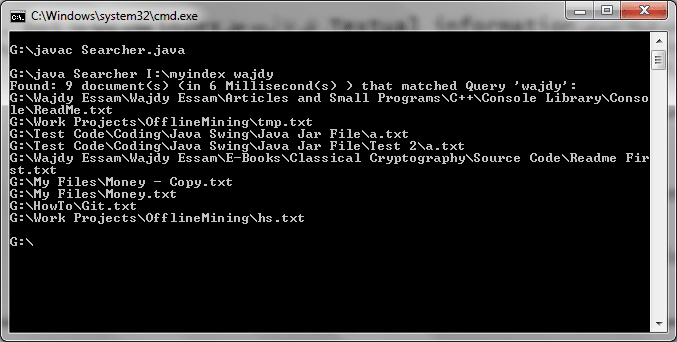
يمكنك أن تقوم الأن بالبحث في هذا الindex ملايين المرات والسرعة كما هي بالطبع.. في البداية قد تدفع ثمن عمل index خصوصا للأقراص الضخمة ، لكن حينها البحث سيكون سريع جدا جدا. هكذا يعمل أغلب محققي الجرائم الالكترونية والبرامج التي يستخدموها، حيث يقوموا بأخذ نسخه من الهارديسك image (يقوموا بأخذ أكثر من نسخه في الحقيقة).. بعد ذلك يقوموا بعمل index لجميع الملفات (txt,pdf,html,,,etc) ومن ثم يتم البحث فيها باستخدام keywords معينة أو باستخدام predefined list .. هذه احدى تطبيقات الindex الجيدة بالمناسبة .
المشكلة الان أن الindex لا يتعرف الا على النصوص فقط، هذه ليست مشكلة ففي جافا توجد مكتبات لأي شيء.. html parser و pdf parser و xml parser ، بل في الحقيقة يوجد الكثير جدا من المكتبات، جرب أن تبحث حول HTML parsers في جافا وستجد على الأقل 8 مكتبات! فهم المكتبة المناسبة واستخدامها أمر مهم أيضا سنتطرق له ان شاء الله فيما بعد..
حاليا lucene النسخة الجديدة اصبحت تدعم ملفات pdf (تستخدم pdfparser نيابة عنك) .. وربما كانت الخطة لمطوري lucene أن يتم استخدام جميع تلك الparsers حتى يتم التسهيل على المطورين. ولكن هنا حدث تطور جيد حيث انبثق مشروع جديد داخل Lucene اطلق عليه Tika ، من خلال هذه المكتبة يمكنك ان تقوم بعمل index في lucene لأي ملف تريد ، حيث تدعم هذه المكتبة أكثر من 15 format للملفات.. بالتالي عند استخدامك للTika فهي تقوم بمعرفة نوع الملف ثم اختيار الparser المناسب (الجميل في الأمر أن التحقق من الملف يتم عن طريق الFile Signature وليس امتداد الملف).. المكتبة Tika حديثة نسبيا ولا يوجد حتى ملف jar جاهز للاستخدام.. فعليك ببناء المكتبة بنفسك باستخدام Meaven اذا أردت..
Tika كانت مجرد البداية، تولدت الأن من lucene المكتبة solr والتي تستطيع استخدامها من خلال تطبيق الويب ، حيث تقدم لك خدمات lucene على طبق من ذهب (indexing + searching) وخدمات Tika الوليدة أيضا على طبق من فضة (indexing many files foramt) .. أعتقد أن مبرمجي الويب سعيدين جدا بهذه الاضافة!
النهاية لم تكن بSolr ، فالملكة mahout قد نضجت الان تحت lucene وهي مكتبة data mining و Collaborative Filtering ، فمن خلالها تستطيع عمل عمل clustering للبيانات الموجودة في الindex ،و يمكنك فلترتها بطرق الذكاء الاصطناعي..
كانت هذه لمحة سريعه حول مشروع lucene وبناتها، أمل ان تكون قد استحوذت هذه المكتبة على انتباهك..
كتب الموضوع في نسخه لوسين 3 والا وصلنا لنسخه 4.5 ولكن المفهوم والفكرة واحدة.



شكرا على هذا المقال. بدأت العمل على لوسين و أعطيتني فكرة جيدة عن المكتبة و الأشياء المتعلقة بها.
لدي سؤال واحد يتعلق بدعم اللغة العربية. يدور بعض الكلام أن المطور قد يواجه بعض الصعوبات للبحث في البيانات باللغة العربية و أن تكييف البيانات المدخلة و كلمات البحث ضروري لتعمل لوسين بالشكل المتوقع. هل توافق على هذا؟ و ان كنت توافق, ما هي التحديات التي قد نواجهها لدعم اللغة العربية؟
شكرا!
بشكل عام هي تدعم العربيه جيداً في الفهرسه ، واي نص بغض النظر عن اللغه يجب أن يعالج (الهدف استخراج Terms قابله للفهرسه على حدة) قبل ان يتم فهرسته حتى يعمل المحرك بشكل أفضل..
بالنسبة لمعالجة النصوص فقد وفرت لوسين عدة Analyzers في المكتبة ولكن لا يوجد واحد يعمل مع الجميع وقد تحتاج لأن تكتب واحد خاص بك ان تطلب الأمر، مثلاً من الامور الواجب عملها قبل الفهرسه هو حذف كل الStop words الموجودة مثل حروف الجر والعله ، ارجاع الكلمة لأصلها Stemming ، حذف التشكيل اذا كانت اللغه بها ذلك، تقسيم النص الى كلمات، قد تريد استخراج الأرقام ، والايميلات ، الاسماء المركبة والخ من المعالجة التي ترغب بها، وقد تجد احياناً Analyzer يناسب حالتك وقد لا تجد ويتطلب أن تقوم بكتابته وأحياناً تحتاج لاعطائه الكلمات,,
مثلاً قبل الفهرسه قد تريد حذف الStop words من النص فيوجد في لوسين StopAnalyzer موجود ويعمل جيداً ولكن المشكلة انك عليك بتزويده بالكلمات من ملف أو اي مصدر أخر حتى يقوم بمسحها من النص الأصلي..
أما في ال Stemming فكان الأمر صعب بالنسبة للعربيه، ولكن هناك بودار خير حيث أن بعد الاصدار 2.9 فالمكتبة تحتوي على Arabic Stammer يعيد الكلمة الى جذرها وان لم أكن قد جربته مسبقاً.
بالنسبة للتشكيل فقد لا توفر Lucene هذا الأمر فهذه المشكلة Language Dependent وقد لا تدعم لوسين معالجة كل اللغات في وقت قصير وانما يحتاج لاسهام المبرمجين، وصراحة لست على اطلاع بالأبحاث العربية في هذا المجال، لكن ربما يكون هناك Contribution لهذا الأمر في لوسين أو كورقة اخرى وربما تكون فرصه جيدة للمبرمجين بعمل Implementation لها في لوسين..
شكراً لك.
عجيبه مقالتك … تسلم … لكن نوضح ان ملف jar هو مكتبة اكواد جافا ما اعرف شنو استخدمها .. كذلك نحتاج انترفيس ابسط للكود … اعتقد موجود حاليا
مشكور على الشرح, أعتقد SOLR بالنسبة للغة العربية أفضل من ناحية البحث وإرجاع الكلمة لأصولها.
بارك الله فيك وبالأخوة المشاركين في التعليقات بس أود أن أعرف اذا قام أحدكم بتجربة الوسين مع اللغة العربية وكيف كانت النتائج وما هي الآلية التي يتبعها في stemming هل يرجع الكلمة إلى أصلها أو جذرها؟
buy canadian enclomiphene online
cheap enclomiphene australia pharmacy
kamagra en paris
réduction en ligne kamagra
androxal best price
buy cheap androxal price from cvs
buying dutasteride buy in the uk
get dutasteride purchase prescription
compare flexeril cyclobenzaprine prices
how to buy flexeril cyclobenzaprine buy generic
get fildena cheap genuine
get fildena no prescription usa
online order gabapentin canada how to buy
buy cheap gabapentin canadian online pharmacy
ordering staxyn cost insurance
pfizer staxyn price
online order itraconazole uk online pharmacy
cheapest buy itraconazole generic free shipping
how to buy avodart cost at costco
order avodart generic pharmacy online
how to buy rifaximin canadian sales
how to order rifaximin where to purchase
Ordering xifaxan online without a perscription
cheap xifaxan real price
obecný kamagra v nz
comprar kamagra en espana
811bet7, huh? Gave it a spin last night. Solid platform, decent odds. Nothing earth-shattering, but reliable. Here’s the link: 811bet7
BJ88dangnhap .net, guys! Quick login and I got straight into the action. No annoying delays. Check ’em out for sure! bj88dangnhap
Alright, alright… so I stumbled upon u888u888cool.com. Name’s a bit…out there, but surprisingly, it’s not bad! Found some unique stuff I haven’t seen elsewhere. Worth a look if you’re bored. Here’s the link: u888u888cool