جميعنا نستخدم محركات البحث عشرات المرات في اليوم الواحد، وقد نضجر في حال لم نستطيع الحصول على ما نريد في أول ثواني بعد عملية البحث، ولكن هل تسائلت يوماً كيف يعمل هذا المحرك وكيف يستخرج النتائج المطابقة التي تريدها؟ هل تسائلت كيف يمكن أن يرتب محرك البحث تلك النتائج بحيث يظهر ذلك المحرك النتائج الأقرب Relevant لاستعلامك؟

كيف تعمل محركات البحث
اذا نظرت للصورة اعلاه سوف تجد مثال لترسانه من ال Data Center التي توجد في اي شركة تختص بالعمل في مجال محركات البحث، كل من هذه الداتا سنتر تحتوى على مئات أو الالاف السيرفرات بالاضافه الى تجهيزات الشبكة وغيرها من الاجهزة، ولكن كل هذه التجهيزات والأجهزة بدون خوارزمية لاسترجاع تلك المعلومات Information Retrieval سوف تكون بلا قيمة أو فائده تذكر.
في هذه المقالة سوف نتحدث عن الخوارزمية المستخدمه في كل مرة تقوم بعملية البحث، وهي تبدأ بعد كتابتك للكلمة التي تريد البحث عنها وضغط زر البحث لكي تبدأ أول مرحلتين هما مرحلة البحث عن الصفحات التي احتوت على ما تريد Matching ومرحلة ترتيب تلك النتائج واظهار الصفحات الأكثر صلة بموضوعك Ranking سيتم الحديث عن خوارمية Page Rank والتي رفعت قوقل للقمة في مقالة أخرى.
البحث والمطابقة Matching والترتيب Ranking
لنبدأ في طرح مثال وهو البحث عن الجملة London bus timetable ولننظر للصورة ادناه وستجد أن مرحلة المطابقة Matching ما هي الا للإجابه على السؤال “ما هي الصفحات التي تحتوى على تلك الجمل” بمعنى كل الصفحات التي احتوت العبارة London bus timetable.

الشكل أعلاه يبين المرحلتين عند البحث: مرحلة ال matching وقد ترجع هذه العملية ملايين الصفحات Hits التي احتوت على تلك العبارة والتي تحتاج لترتيب على حسب اهميتها وتقاربها لما يريده المستخدم Relevance وتسمى هذه المرحلة بال Ranking.
بشكل عملي أغلب محركات البحث تقوم بهذه الخطوتين في خطوة واحدة لكن كل منهم له هدف لوحده عن الثاني لذلك يمكن أن يدرسوا بشكل مفصول على أساس مرحلتين وتبدأ الثانية بعد أن تنتهي الاولى من عملها.
أغلب الاستعلامات التي تقوم بها لها مئات أو الالاف النتائج Hits والمستخدم يفضل أن ينظر لمجموعه من الصفحات في النتيجة مثلاً أول 10 صفحات في النتائج، لذلك على محرك البحث أن يختار أفضل نتائج من العدد الكلي الضخم الناتج من المرحلة الاولى بالاضافة الى عرضهم بطريقة مرتبة بحيث تكون النتيجة الاولى هي التي تحتوى على أقرب ما يريده المستخدم والتي تليها ثم التي تليها وهكذا..
مرحلة اختيار الصفحات تسمى Ranking وهي مرحلة مهمه تاتي بعد مرحلة ال Matching. وفي عالم شركات محركات البحث فإن خوارزمية الRanking قد تحدد مصير ذلك المحرك هل سوف ينجح أم لأ (لو رجعنا للوراء في 2000 سنجد أن استحواذ السوق في محركات البحث كان متساوياً للشركات الثلاثه Google و Yahoo و MSN بنسبة 30% تقريباً في السوق الامريكي، لكن بعدها قامت Google بتحسين محركها مما أدى لسقوط ياهو و MSN لنسبة 20% وهذا التحسين كان بسبب التحسين في خوارزمية ال Ranking). لذلك خوارزمية ال Ranking تعتبر من المؤثرات القوية في محركات البحث.
ماذا تعرف عن الفهرسة Indexing
شركة Google لم تكن الأولى في خدمة محركات بحث، بل سبقتها عده شركات مثل Infoseek و Lycos في منتصف التسعينيات وتبعتهم AltaVista والتي كانت رائجه ذلك الوقت بسبب قوة محركها الذي استطاع البحث على كل الصفحات في الويب وسرعة استخراجه للمعلومات، والسؤال كيف تم ذلك، الجواب بكلمة واحدة هي الفهرسة Index.
مفهوم الفهرسه Indexing هو أحد أهم الأساسيات وراء محركات البحث وهو مفهوم قديم من قبل ظهور محركات البحث وعلوم الحاسب، وفي الغالب عندما نقول الفهرسه فهذا يذكرنا بالفهرس الموجود في اواخر الكتب والذي من خلاله تستطيع الرجوع للصفحة التي فيها الكلمة التي تبحث عنها.
الفهرس Index في محركات البحث يعمل بنفس الفكرة، فالصفحة هنا لن تكون صفحة في الكتاب وانما في الويب وسيتم اسناد رقم لكل صفحة في الويب (حتى ان كانت بلايين الأرقام فالحواسيب جيدة عندما نتعامل بلغه الأرقام).
حتى نعرف كيف يتم عمل الفهرسه ، لنفترض أن الويب مكون من 3 صفحات كما في الصورة التالية ، وتم اعطاء رقم لكل صفحة

يتم بناء الفهرس عند طريق عمل قائمة الكلمات التي تكررت في كل الصفحات ومن ثم ترتيب تلك الكلمات أبجدياً (وسوف نسميها Word List) وهي التي تتكون من الكلمات a و cat و dog الخ من الكلمات التي تكررت في الصفحات الثلاثه، وبجانب كل من الكلمات سيتم وضع رقم الصفحة التي تكررت في هذه الكلمة، مثلاً الكلمة on تكررت في الصحفة 1 و 2 ، وهكذا للجميع.
بهذه الفكرة البسيطة يستطيع محرك البحث ايجاد الصفحات لاستعلامك، مثلاً قمت بالبحث عن cat سوف يبدأ المحرك بالذهاب لل word list وايجاد الكلمة cat سريعاً لأن القائمة مرتبة ابجدياً وبعدها يتم ايجاد الصفحات التي تكررت فيها الكلمة وهي هنا 1 و 3، والمحركات الحديثة بالطبع تقوم باظهار النتيجة بشكل جيد عن طريق اظهار مختصر سطر أو اثنين من كل صفحة في النتيجه لكن سوف نتجاهل هذا الامر ونركز عن كيف يعرف محرك البحث أن الصفحة هذه هي التي تريد.
نأخذ مثال أخر للبحث عن جملة من كلمتين cat dog وهذا يعني الصفحات التي احتوت على cat و dog وبنفس الأسلوب سيتم البحث عن الصفحات التي تكرر فيها cat وهي 1 و 3 والتي تكرر فيها dog هي 2 و 3 والان سيتم التظر لهذه النتيجة والبحث عن اي صفحة تكررت في القائمتين وهي الصفحة رقم 3. وبنفس الفكرة الاستعلامات عن الجمل من أكثر من كلتين مثلاً cat the sat والنتيجة هي الصفحة 3 و 1 (يمكنك اكتشاف ذلك بنفسك كتمرين).
قد تتسائل بأن هذا الأمر بسيط وهذا يعني أنه يسهل بناء محركات البحث؟ الفكرة اعلاه تجدي نفعاً مع البحث في الاستعلام من كلمة word query أو أكثر multi-words query ولكن لا تنفع لكي تكون محرك بحث مثل المحركات التي نراها اليوم، والسبب ونحصره الان في نقطة واحدة ونركز عليها وهي انه لا يدعم البحث عن الجمل phrase queries.
ال Phrase Query هي عندما تبحث عن وجود نص بعينه في الصفحة وليس مجرد البحث عن كلمة هل موجودة في الصفحة أم لأ، وفي أغلب المحركات يكون من خلال كتابة النص بين علامتي التنصيص “هنا”، على سبيل المثال البحث عن “cat dog” يختلف عن البحث cat dog فالأول يبحث عن وجود cat dog بنفس الشكل أم الثاني يبحث عن وجود cat dog في الصفحة بغض النظر عن مكان وجودهم في الصفحة (بأي ترتيب). لو طبقنا هذه الاستعلامات على الصفحات اعلاه سنجد أن الاستعلام cat sat يعطي الصفحات 1 و 3 بينما الاستعلام “cat sat” يعطي الصفحة رقم 1 فقط.
كيف حصل محرك البحث على النتيجة عندما تم الاستعلام عن “cat sat” ؟ كما يبدوا اننا سنستخدم نفس الطريقة ونقوم بالبحث عن cat (وتخرج الصفحات 1 و 3) لها وللكلمة sat (تخرج النتيجة 1 و 3) ، هنا سيقع محرك البحث البدائي في المشكلة ، فهو الآن يعلم أن الكلمتين تكررتا في الصفحات 1 و 3 ولكن كيف يعلم أنهم جائا متتابعات وفي الترتيب الصحيح؟
قد تقول يمكن للمحرك أن يذهب وينظر للصفحات نفسها ويتأكد من أن الجملة موجودة بها وقد يعمل هذا ولكن بكل تأكيد الحل غير عملي اطلاقاً لأن المحرك سوف يبحث عن الجملة في كل صفحة كانت تحتوى على عباره من العبارات في الاستعلام ، وتذكر أننا نعمل على مثال صغير مكون من 3 صفحات أي بشكل طبيعي سوف تكون هناك الالاف من الصفحات يحتمل أن ان تحتوى على العبارة كاملة.
فكرة اضافة موقع الكلمة في ال Index
حل المشكلة السابقة كان مفتاحاً لجعل المحركات تدعم البحث الذي يحتوى على النصوص، فالفهرس لن يحتوى على ارقام الصفحات فقط ولكن ايضاً موقع الكلمة في تلك الصفحات، الصورة التالية تبين الفهرس المكون من 3 صفحات مع مواقع indexes الكلمات في تلك الصفحات.
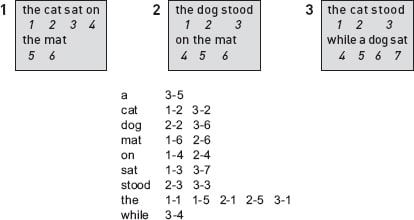
الشكل يبين ال3 صفحات بعد فكرة اضافة موقع الكلمة للفهرس
لاحظ الجدول اسفل الصورة، وستجد a بجانبها 3-5 وهذا يعني أن الكلمة a تكررت في الصفحة الثالثة في الخانه 5. انظر للكلمة the ستجد أنها تكررت في الصفحة 1 الخانه 1 والصفحة 1 الخانه 5 وهكذا.
بما أنه تم اضافة فكرة موقع الكلمة word location trick لكي يتم دعم البحث بالجملة phrase queries، فلنعيد المثال مرة اخرى بهذا التصميم الجديد للفهرس، ونبحث عن الكلمة “cat sat” ؟
اول خطوة كما في السابق هي معرفة كل مواقع كل كلمة على حدة في الفهرس، والكلمة cat تكررت في 1-2 و 3-2 أما الكلمة sat فهي 1-3 و 3-7، والان نحن نعلم ان الصفحات في النتيجة هي 1 و 3، ولننظر للصفحة 1 وستجد أن الكلمة cat تكررت في الخانه 2 والكلمة sat تكررت في الخانه 3 وهكذا تعلم أنها جائت بعدها وهو كما تبحث عنه، هكذا الصفحة 1 احتوت على النتيجة الصحيحة.
هكذا بهذه الفكرة word location trick استطعنا دعم ال phrase queries بدون الحاجة لاعادة قرائة الصفحات والبحث مجدداً، اضافة الى أنها تفيد في أمور أخرى مثل ايجاد الكلمات القريبة من بعضها عن طريق الكلمة NEAR (وهي كانت مدعومة في محرك بحث Altavista)، في مثالنا السابق لو بحثنا عن cat NEAR dog ستخرج 1-2 و 3-2 لل cat و 2-2 و 3-6 لل dog وهكذا تعلم أن الصفحة 3 هي النتيجة الوحيدة لهذا الاستعلام والفرق هو 4 اذاً الكلمة dog تأتي بعد 3 كلمات من cat.
هكذا بهذه الفكرة دعمنا ال Phrase Queries وال Near Queries والتي لم تعد مهمه هذه الايام في محركات البحث ولا توجد محركات تدعمها هذا بالنسبة لنا كمستخدمين، ولكن من الداخل فان عملية ال Near Queries مهمه خلف الستار ولمعرفة لماذا نحتاج لتسليط الضوء حول المهمه الثانية من مهام محرك البحث وهي ال Ranking.
ترتيب النتيجة Ranking والاستعلام NEAR
قليل قليل كنا نتحدث عن مرحلة البحث Matching (أيجاد كل النتائج hits من الاستعلام) وذكرنا أن عملية ال Ranking هي الأساس لأي محرك بحث يحترم نفسه هي هنا يتم ختيار بعض من ال hits حتى يتم عرضها للمستخدم.
لكي نقوم بنتاولها بشكل جيد دعنا نبدأ بالحديث عن ال Rank وعلى ماذا يعتمد ؟ والسؤال هو ليس “هل هذه الصفحة تحتوى على الاستعلام” وانما “هل هذه الصفحة مقاربة relevant للاستعلام”؟ في علم الحاسب يتم استخدام Relevance لوصف كيف تبدوا الصفحة متعلقه باستعلام معين.
مثال: لتكن انت مهتم بالبحث عن مسببات مرض الملاريا وقمت بالبحث عنها في المحرك بالعبارة malaria cause ولنفرض أن هناك صفحتين احتوت على تلك العبارات موجودة في الصورة أسفل

الشكل يبين الصفحتين الناتجة من البحث عن مرض الملاريا مع جزء من الفهرس التي تم بنائه
لو تمعنت النظر في هذه الصفحات ستجد أن الاولى تتحدث عن مرض الملاريا أما الثانية فهي لا علاقه لها بالأمر وانما صدف أن احتوت على تلك الكلمتين وهكذا الصفحة الأولى هى اكثر صلة لما يريده المستخدم relevant من الصفحة الثانية. لكن المشكلة ان الحواسيب ليسوا كالبشر ولا توجد طريقة سهله لكي يفهم هذا النص، فهل هذا يعني انه يستحيل ان يقدر كل من هذه الصفحات Ranking بشل صحيح ؟
لحسن الحظ سوف نستخدم طريقة سهله لعمل ذلك وفكرتها هي أن الصفحة التي تحتوى على الكلمات بجانب بعضهم NEAR تكون اكثر صلة relevant من الصفحات التي تحتوى على الكلمات متباعدة. في مثال الملاريا الصفحة الأولى كانت الكلمتان cause و malaria متتابعتين أما الصفحة الثانية الفرق هو 17 (وتذكر سوف يتم ايجاد ذلك من خلال النظر للindex وليس للصفحات والسبب باستخدام فكرة موقع الكلمة في الفهرس).
هكذا حتى لو لم يستطيع الحاسب فهم المحتوى يمكنه تخمين ان الصفحة 1 أقرب للاستعلام من الصفحة 2 لأنها احتوت على العبارات بشكل متقارب.
الى هذه اللحظة كنا نتحدث عن صفحات بسيطة جداً، وكما تعلم أن الصفحات في الويب تحتوى تكون بلغه معينة أو لها structure معين مثل العنوان والمحتوى والروابط والصور وغيرها، وسوف ننظر الآن كيف ينظر المحرك لتلك الامور في الصفحة، ولتبسيط الامر سوف نفترض أن الصفحة لها عنوان title ولها محتوى body، الصورة التالية تبين 3 صفحات لها structure.

اي صفحة في الويب مكتوبة في الغالب بلغة HTML والتي لها tags معينة لتحديد العنوان والروابط والخ، وسوف نسميها بشكل عام metawords ولننظر للصفحات اعلاه بعد أن قمنا بتحديد تلك ال metawords حتى تكون أقرب للواقع.

عندما تنبي محرك البحث فيمكنك اضافه كل ال metawords ايضاً في الفهرس، الشكل التالي يبين اضافه ال metawords في الفهرس للصفحات السابقة وسوف نطلق عليها “فكرة اضافة الmetawords”

قد تظن أن فكرة اضافة ال metawords ليست ذا فائده ولكنها في الحقيقة عكس ذلك، حيث هي مهمه لتقديم خدمات بحث جيدة . سوف نأخذ مثال ولكن قبله سوف نفرض أن المحرك يدعم البحث من خلال IN ك IN TITLE للبحث في العنوان مثلاً boat IN TITLE للبحث عن الصفحات التي بها boat في العنوان.
مثال: اننا نبحث عن dog IN TITLE في الصفحات اعلاه، فأول خطوة هي معرفة نتيجة dog وهي 2-3 و 2-7 و 3-11 وبعدها أخذ نتيجة <titleStart> وهي 1-1, 2-1, 3-1 ونتيجة <titleEnd> وهي 1-4,2-4,3-4 ، النتيجة توجد في الصورة التالية وتجاهل الدوائر والمربعات حالياً:

سوف يبدأ المحرك بالنظر لنتيجة dog وينظر هل هي داخل العنوان أم لأ، النتيجة الأولى 2-3 عليها دائرة في الصورة اعلاه وهي أن الكلمة dog تكررت في الصفحة 2 الخانه 3 بعدها يتم فحص <titleStart> عن اي صفحة تبدأ ب 2 وسيجد المحرك أن العنوان في الصفحة 2 وايضاً يبحث في <titleEnd> عن الصفحة 2 وسيجد أنها انتهت في الخانه 4 (عليهم دوائر في الصورة السابقة).
الخطوة الاخيرة هي سهله لأن 3 أكبر من 1 وأصغر من 4 اذاً نحن نعلم ان الكلمة dog موجودة في العنوان في الصفحة 2.
قم بالنظر الان في الصفحة 3 وستجد أن كلمة dog موجودة في الخانه 11 بينما العنوان بدأ في 1 وانتهي في 4 اذاً الكلمة dog ليست موجودة في عنوان صفحة 3.
هكذا نجد أن ال metawords تسمح لمحرك البحث بأن يبحث داخل تركيبة الملف بسهولة، وفي الغالب المستخدمين لا يقوموا بذلك مباشرة ولكن يمكن للمحرك أن يقوم بها داخلياً، مثلاً قمت بالبحث عن dog فيمكن للمحرك أن يقوم بعمل dog IN TITLE من الداخل والسبب أن الصفحات التي تحتوى على dog في العنوان قد تكون أقرب وأكثر صلة لاستعلامك من الصفحات التي تحتوي على dog في الbody.
خلاصة
الIndexing وال Matching هي ليست كل شي في محرك البحث فبناء محركات البحث أمر شاق والمنتج النهائي يحتوي على الكثير من التفاصيل الأخرى مثل الCrawler وغيرها، ما تم استعراضه هنا فكرة word location trick و metawords trick ما هم الا اجزاء من محركات البحث حول كيفية البحث واستخدام الفهرس، وال metawords كانت مساعدة لمحرك البحث AltaVista وقت ظهوره ولكن كما ذكرنا ان البحث والMatching ما هي الا نصف الطريق في محرك البحث وتبقى التحدى الاخر وهو ال Ranking والذي ابدعت في قوقل واخرج محرك Altavista خارج اللعبة وهو ما سيتم تناوله ولكن في المقالة التالية ان شاء الله.



الحقيقة مش لاقي كلام إني اشكرك بيه على هذه السلسلة , اظنها ستكون من اروع المصادر العربية في هذا المجال
شكراً جزيلاً
شكرا على هذه المقالة ولكن عندي سؤال وهو كيف يضيف محرك البحث صفحة على الويب الى فهرسته، بمعنى لو فلان انشئ موقع على الانترنت بعد عدة ايام تجدها مفهرسة على قوقل مثلا، كيف استطاع محرك البحث الوصول لهذه الصفحة ؟
محرك البحث لن يعرف بوجود موقع إلا إذا نشرته بطريقة ما كأن تضعه في توقيع مثلاً، عندما يزور الموقع يقرأ رابط الموقع في الصفحة وسيضيفه لديه ويرسل برامج تحلل الصفحة لأرشفتها -بوتات- ومن ثم سيظهر في محرك البحث.
buy androxal cost effectiveness
buy androxal generic does it works
cheap enclomiphene how to purchase viagra
ordering enclomiphene buy in london
ordering rifaximin cheap from india
generic rifaximin capsules price comparison
buy xifaxan cheap trusted
discount xifaxan american express canada
cheap staxyn cheap online pharmacy
buy cheap staxyn generic ireland
purchase avodart purchase in australia
buying avodart uk sales
buy dutasteride purchase prescription
cheapest buy dutasteride canadian sales
buy flexeril cyclobenzaprine cost at costco
discount flexeril cyclobenzaprine using mastercard
buy gabapentin generic overnight shipping
No r x needed for purchasing gabapentin
kamagra objednávejte přes noc
dělá obecný kamagra z kanady práce
achat kamagra generique
medicament kamagra pharmacie en ligne en france achat
online order fildena australia online generic
cheap fildena purchase toronto
buy cheap itraconazole generic alternatives
cheapest buy itraconazole generic lowest price
Finding the right 7gamesentrar can be a pain, but this one was no problem. Smooth and simple login process. If you’re already using 7games, this is a good way in. Give 7gamesentrar a try.
U888U888COOL on .com, huh? Had some fun times there. Fair play and a smooth interface. Worth a peek. u888u888cool
Alright folks, 80gamesvip showed promise. The VIP aspect is kinda cool, but the game selection needs a bit more oomph. Still, worth checking out if you’re looking for something a bit different. You can find it at 80gamesvip.
Yo folks, check out Appbetano, they have it all! Playing online is the best, try appbetano!!
Betanobetb. That’s my cup of tea! Having a grand old time, betting on the matches! Try out betanobetb yourself!
Heard Diamante Casino has a no deposit bonus going on. Gotta check out diamante casino bono sin depósito and see if it’s worth the hype!